So how does CFUNCTYPE work, anyway (or: why is libffi like this)
I've been trying to write about crackstation, a challenge from the 2023 FE-CTF qualifiers, for a while. In short, it's an interpreter/JIT for a custom bytecode implemented in Python, that executes every instruction by first translating it to x86_64 machine code and jumping back and forth between Python-land and native-land. There's a lot of interesting stuff going on in there, and this post is not about it.
However, it contains a snippet roughly along these lines (cleaned up and deobfuscated):
@ctypes.CFUNCTYPE(None)
def my_function():
print("please imagine actual function")
code = b''.join((b'\x55\x48\x89\xe5\x48\x83\xe4\xf0\x48\xb8', my_function, b'\xff\xd0\xc9\xc3'))
This code is fairly innocious in context - it's what it inserts after every instruction to jump back into Python-land so it can compile the next instruction.
But... is that concatenating a Python function with x86 assembly? What's going on?
It turns out the CFUNCTYPE decorator has a lot of magic behind the scenes. For example, we can interpret it as bytes, and it'll magically transform itself into a function pointer, already encoded in little-endian for us:
>>> bytes(my_function)
b'\x10PI\x18\x83\x7f\x00\x00'
>>> hex(int.from_bytes(my_function, "little"))
'0x7f8318495010'
And if we disassemble the machine code from earlier, it's just calling that function pointer like it was any other native function:
55 push rbp
48 89 E5 mov rbp, rsp
48 83 E4 F0 and rsp, 0xfffffffffffffff0
48 B8 10 A0 1B F3 AF 7F 00 00 movabs rax, 0x7faff31ba010
FF D0 call rax
C9 leave
C3 ret
(The exact assembly here isn't relevant, it's mostly just stack housekeeping. Please pretend it's the same address as well.)
But... surely, this can't work. We're mixing two different worlds - interpreted and native. You can't just convert one into the other and expect it to work, just like that, right?
The Python function is bytecode that exists in memory and gets interpreted by the CPython runtime; at no point (at least until 3.13 adds a JIT) does it ever exist as anything resembling native code.
There's a C function, PyObject_Call, that calls a Python function given a pointer to the function object in memory, but there's a lot of machinery going on to support that. The object is a lot more than just an address to some code - it needs to know about the garbage collector, the runtime state, the GIL, everything about the Python environment.
There's all sorts of reasons why this just isn't right. There's a reason C doesn't have closures, and why they require extra wrangling in most other compiled languages.
And yet... here, let's try something wild:
import ctypes, mmap
gc_root = []
def make_function(my_string):
@ctypes.CFUNCTYPE(None)
def inner():
# look ma, proper closures!
print(f"inner function: {my_string}")
gc_root.append(inner)
return ctypes.cast(inner, ctypes.c_voidp)
def run_function(ptr):
# just a function pointer! really!
assert type(ptr) == ctypes.c_voidp
print(f"> running function: 0x{ptr.value:x}")
# (this is mostly unnecessary and just to prove the point that this can really just be called from native code)
code = b''.join((b'\x55\x48\x89\xe5\x48\x83\xe4\xf0\x48\xb8', ptr, b'\xff\xd0\xc9\xc3'))
mm = mmap.mmap(-1, len(code), flags=mmap.MAP_SHARED | mmap.MAP_ANONYMOUS, prot=mmap.PROT_WRITE | mmap.PROT_READ | mmap.PROT_EXEC)
mm.write(code)
ctypes_buffer = ctypes.c_int.from_buffer(mm)
function = ctypes.CFUNCTYPE(None)(ctypes.addressof(ctypes_buffer))
function()
run_function(make_function("hello world"))
run_function(make_function("all your funcs"))
run_function(make_function("are belong to us"))
$ python test.py
> running function: 0x7f31dc4cb010
inner function: hello world
> running function: 0x7f31dc4cb050
inner function: all your funcs
> running function: 0x7f31dc4cb090
inner function: are belong to us
Clearly, there's some magic going on here. What, exactly, lives at that pointer? How does it create more functions at runtime? Is it actually generating machine code at runtime, or are there more tricks going on? (spoiler: there are many)
CFUNCTYPE
Let's step back a little bit here.
Consider this code:
@ctypes.CFUNCTYPE(None)
def my_function():
print("please imagine actual function")
The decorator syntax desugars to something like this:
my_functype = ctypes.CFUNCTYPE(None)
def my_function():
print("please imagine actual function")
my_function = my_functype(my_function)
The documentation of CFUNCTYPE, from the ctypes documentation reads as follows:
ctypes.CFUNCTYPE(restype, *argtypes, use_errno=False, use_last_error=False)The returned function prototype creates functions that use the standard C calling convention. The function will release the GIL during the call. If use_errno is set to true, the ctypes private copy of the system errno variable is exchanged with the real errno value before and after the call; use_last_error does the same for the Windows error code
CFUNCTYPE is a "factory function" returning a "function prototype". Above this is a paragraph explaining what a function prototype is (emphasis mine):
Foreign functions can also be created by instantiating function prototypes. Function prototypes are similar to function prototypes in C; they describe a function (return type, argument types, calling convention) without defining an implementation. The factory functions must be called with the desired result type and the argument types of the function, and can be used as decorator factories, and as such, be applied to functions through the @wrapper syntax. See Callback functions for examples.
This makes sense - compiled code has no concept of "types" or "arguments" or "return values", really, so the calling code needs to know what it'll be working with in advance. There are a few different conventions for argument locations and return values - their distinctions aren't relevant right now, but like the documentation says, CFUNCTYPE is the one we want for the "standard C calling convention" (whatever that is...).
So, what can we do with a function prototype?
In most cases, we'll use it to call C functions from Python. If we call our prototype with the address of a C function, it'll return an object we can use to call it. Let's try it with a few simple functions from the C standard library:
import ctypes
libc = ctypes.CDLL("libc.so.6")
rand_ptr = ctypes.cast(libc.rand, ctypes.c_voidp).value
puts_ptr = ctypes.cast(libc.puts, ctypes.c_voidp).value
print(f"rand() address: {rand_ptr:x}")
print(f"puts() address: {puts_ptr:x}")
rand_functype = ctypes.CFUNCTYPE(ctypes.c_int) # int rand()
puts_functype = ctypes.CFUNCTYPE(None, ctypes.c_char_p) # void puts(char*)
my_rand = rand_functype(rand_ptr)
my_puts = puts_functype(puts_ptr)
random_number = my_rand()
message = f"my random number is: {random_number}"
my_puts(ctypes.create_string_buffer(message.encode()))
$ python test_rand.py
rand() address: 7fd87690dc80
puts() address: 7fd876945670
my random number is: 1804289383
$ python test_rand.py
rand() address: 7fab2d19ac80
puts() address: 7fab2d1d2670
my random number is: 1804289383
We use CDLL to resolve the addresses of rand and puts from libc. ctypes helpfully hands us callable functions right away, but we'll cast them directly to integers and work with those instead, for demonstration purposes.
If we run this script more than once, we'll see that the addresses returned won't be identical. This is due to address space layout randomization: there are many security advantages to not having addresses of important functions be easily predictable.
However, we don't want to call C functions from Python, we want to call Python functions from C native code!
If we read a little further in the documentation, we'll encounter what we actually want, here:
Function prototypes created by these factory functions can be instantiated in different ways, depending on the type and number of the parameters in the call:
prototype(address)
Returns a foreign function at the specified address which must be an integer.
prototype(callable)
Create a C callable function (a callback function) from a Python callable.
This is what we were doing earlier! Calling our function prototype with a Python function in order to make a C callable function.
Let's take a closer look:
import ctypes
my_functype = ctypes.CFUNCTYPE(None)
def my_function():
print("please imagine actual function")
my_function = my_functype(my_function)
my_function_ptr = ctypes.cast(my_function, ctypes.c_void_p).value
print(f"my function: {my_function_ptr:x}")
$ python test_cfunc.py
my function: 7f235ea94010
So, what's going on when we call my_functype(my_function)? How does it get to the pointer that it eventually returns?
There's a little extra information about this functionality in the Callback functions section of the ctypes documentation, but it only really provides an example of passing a Python function to qsort in libc. There's a little disclaimer about making sure your functions aren't garbage collected, but other than that, nothing about how this actually works.
But I know one way of finding out how something works...
Reading the source
The implementation of ctypes.CFUNCTYPE can be found in Lib/ctypes/init.py in the Python source code.
Unfortunately, there's not much to glean from it:
_c_functype_cache = {}
def CFUNCTYPE(restype, *argtypes, **kw):
flags = _FUNCFLAG_CDECL
if kw.pop("use_errno", False):
flags |= _FUNCFLAG_USE_ERRNO
if kw.pop("use_last_error", False):
flags |= _FUNCFLAG_USE_LASTERROR
if kw:
raise ValueError("unexpected keyword argument(s) %s" % kw.keys())
try:
return _c_functype_cache[(restype, argtypes, flags)]
except KeyError:
pass
class CFunctionType(_CFuncPtr):
_argtypes_ = argtypes
_restype_ = restype
_flags_ = flags
_c_functype_cache[(restype, argtypes, flags)] = CFunctionType
return CFunctionType
Some handling for the extra keyword arguments (that we'll ignore), a primitive cache for repeated calls with the same arguments, and then it returns an inner class with the actual functionality (wow, a function that returns a class? wonder how that works...).
CFunctionType doesn't have any functionality implemented in Python - it gets its behavior from the _CFuncPtr parent class, which is implemented entirely in C.
We can find the definition of this class in Modules/_ctypes/_ctypes.c, around pycfuncptr_spec:
static PyType_Slot pycfuncptr_slots[] = {
{Py_tp_dealloc, PyCFuncPtr_dealloc},
{Py_tp_repr, PyCFuncPtr_repr},
{Py_tp_call, PyCFuncPtr_call},
{Py_tp_doc, PyDoc_STR("Function Pointer")},
{Py_tp_traverse, PyCFuncPtr_traverse},
{Py_tp_clear, PyCFuncPtr_clear},
{Py_tp_getset, PyCFuncPtr_getsets},
{Py_tp_new, PyCFuncPtr_new},
{Py_bf_getbuffer, PyCData_NewGetBuffer},
{Py_nb_bool, PyCFuncPtr_bool},
{0, NULL},
};
static PyType_Spec pycfuncptr_spec = {
.name = "_ctypes.CFuncPtr",
.basicsize = sizeof(PyCFuncPtrObject),
.flags = (Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC |
Py_TPFLAGS_IMMUTABLETYPE),
.slots = pycfuncptr_slots,
};
Here, we can see the methods defined on this class. Py_tp_call maps to __call__, which handles calling the object like a (Python) function. Py_bf_getbuffer defines how the object is converted to bytes - this is how we could concatenate a C function directly into the byte string with machine code earlier.
The interesting one here is Py_tp_new, which constructs a new CFuncPtr: this is the function we pass our Python function (or C function pointer) to!
Let's take a look at PyCFuncPtr_new, then. I'm going to cut out a lot of the error handling and argument validation for brevity:
static PyObject *
PyCFuncPtr_new(PyTypeObject *type, PyObject *args, PyObject *kwds)
{
PyCFuncPtrObject *self;
PyObject *callable;
CThunkObject *thunk;
// [snip: argument validation]
if (1 == PyTuple_GET_SIZE(args)
&& (PyLong_Check(PyTuple_GET_ITEM(args, 0)))) {
CDataObject *ob;
void *ptr = PyLong_AsVoidPtr(PyTuple_GET_ITEM(args, 0));
if (ptr == NULL && PyErr_Occurred())
return NULL;
ob = (CDataObject *)GenericPyCData_new(type, args, kwds);
if (ob == NULL)
return NULL;
*(void **)ob->b_ptr = ptr;
return (PyObject *)ob;
}
if (!PyArg_ParseTuple(args, "O", &callable))
return NULL;
if (!PyCallable_Check(callable)) {
PyErr_SetString(PyExc_TypeError,
"argument must be callable or integer function address");
return NULL;
}
ctypes_state *st = get_module_state_by_def(Py_TYPE(type));
StgInfo *info;
if (PyStgInfo_FromType(st, (PyObject *)type, &info) < 0) {
return NULL;
}
// [snip: more validation]
thunk = _ctypes_alloc_callback(st,
callable,
info->argtypes,
info->restype,
info->flags);
if (!thunk)
return NULL;
self = (PyCFuncPtrObject *)generic_pycdata_new(st, type, args, kwds);
if (self == NULL) {
Py_DECREF(thunk);
return NULL;
}
self->callable = Py_NewRef(callable);
self->thunk = thunk;
*(void **)self->b_ptr = (void *)thunk->pcl_exec;
Py_INCREF((PyObject *)thunk); /* for KeepRef */
if (-1 == KeepRef((CDataObject *)self, 0, (PyObject *)thunk)) {
Py_DECREF((PyObject *)self);
return NULL;
}
return (PyObject *)self;
}
The first portion of this function handles the case where we pass it a simple function pointer:
if (1 == PyTuple_GET_SIZE(args)
&& (PyLong_Check(PyTuple_GET_ITEM(args, 0)))) {
CDataObject *ob;
void *ptr = PyLong_AsVoidPtr(PyTuple_GET_ITEM(args, 0));
if (ptr == NULL && PyErr_Occurred())
return NULL;
ob = (CDataObject *)GenericPyCData_new(type, args, kwds);
if (ob == NULL)
return NULL;
*(void **)ob->b_ptr = ptr;
return (PyObject *)ob;
}
It creates an empty "generic object", stuffs the pointer we give it in the data buffer (ob->b_ptr), and returns it. The code responsible for calling this pointer will be in PyCFuncPtr_call, but we don't care about that right now.
What happens if we give it a callable (Python function), though?
if (!PyArg_ParseTuple(args, "O", &callable))
return NULL;
if (!PyCallable_Check(callable)) {
PyErr_SetString(PyExc_TypeError,
"argument must be callable or integer function address");
return NULL;
}
ctypes_state *st = get_module_state_by_def(Py_TYPE(type));
StgInfo *info;
if (PyStgInfo_FromType(st, (PyObject *)type, &info) < 0) {
return NULL;
}
This extracts the function prototype info we defined when creating the class it's instantiating. StgInfo seems to be in flux right now - a lot of this code is being refactored between Python 3.12 and 3.13, so I won't dig too deep into it right now - right now it's just "data we need to have".
thunk = _ctypes_alloc_callback(st,
callable,
info->argtypes,
info->restype,
info->flags);
if (!thunk)
return NULL;
self = (PyCFuncPtrObject *)generic_pycdata_new(st, type, args, kwds);
if (self == NULL) {
Py_DECREF(thunk);
return NULL;
}
self->callable = Py_NewRef(callable);
self->thunk = thunk;
*(void **)self->b_ptr = (void *)thunk->pcl_exec;
This code looks a lot like the previous case, where we were just saving a function pointer in an object. We still write to b_ptr, but instead of the pointer we're providing, it's saving thunk->pcl_exec.
Thunk is one of those computer words that kind of mean a lot of things depending on context. I still don't entirely understand the nuances of it. I think it means "closure", sorta, kinda. Let's go with that. It's a function thing.
The important part here seems to be the _ctypes_alloc_callback function: it takes in the Python callable and some argument info, and returns a CThunkObject*, which contains a native function pointer. It's defined in Modules/_ctypes/callbacks.c, so let's take a look. There's some "gunk" in here, various #ifdefs for cross-platform support - I'm going to strip those out for readability, too.
CThunkObject *_ctypes_alloc_callback(ctypes_state *st,
PyObject *callable,
PyObject *converters,
PyObject *restype,
int flags)
{
int result;
CThunkObject *p;
Py_ssize_t nargs, i;
ffi_abi cc;
assert(PyTuple_Check(converters));
nargs = PyTuple_GET_SIZE(converters);
p = CThunkObject_new(st, nargs);
if (p == NULL)
return NULL;
assert(CThunk_CheckExact(st, (PyObject *)p));
p->pcl_write = Py_ffi_closure_alloc(sizeof(ffi_closure), &p->pcl_exec);
if (p->pcl_write == NULL) {
PyErr_NoMemory();
goto error;
}
p->flags = flags;
PyObject **cnvs = PySequence_Fast_ITEMS(converters);
for (i = 0; i < nargs; ++i) {
PyObject *cnv = cnvs[i]; // borrowed ref
p->atypes[i] = _ctypes_get_ffi_type(st, cnv);
}
p->atypes[i] = NULL;
p->restype = Py_NewRef(restype);
if (restype == Py_None) {
p->setfunc = NULL;
p->ffi_restype = &ffi_type_void;
} else {
StgInfo *info;
if (PyStgInfo_FromType(st, restype, &info) < 0) {
goto error;
}
if (info == NULL || info->setfunc == NULL) {
PyErr_SetString(PyExc_TypeError,
"invalid result type for callback function");
goto error;
}
p->setfunc = info->setfunc;
p->ffi_restype = &info->ffi_type_pointer;
}
cc = FFI_DEFAULT_ABI;
result = ffi_prep_cif(&p->cif, cc,
Py_SAFE_DOWNCAST(nargs, Py_ssize_t, int),
p->ffi_restype,
&p->atypes[0]);
if (result != FFI_OK) {
PyErr_Format(PyExc_RuntimeError,
"ffi_prep_cif failed with %d", result);
goto error;
}
result = ffi_prep_closure_loc(p->pcl_write, &p->cif, closure_fcn,
p,
p->pcl_exec);
if (result != FFI_OK) {
PyErr_Format(PyExc_RuntimeError,
"ffi_prep_closure failed with %d", result);
goto error;
}
p->converters = Py_NewRef(converters);
p->callable = Py_NewRef(callable);
return p;
error:
Py_XDECREF(p);
return NULL;
}
After a bit of setup, the first interesting call we encounter is this:
p->pcl_write = Py_ffi_closure_alloc(sizeof(ffi_closure), &p->pcl_exec);
Py_ffi_closure_alloc is just a thin wrapper around ffi_closure_alloc (and on every platform other than macOS/iOS, is #defined as it directly).
Now, ffi_closure_alloc isn't defined in CPython at all! It's from an entirely different library, libffi. We'll get to that in a moment, but let's keep going for now.
Importantly, we can see that it writes to p->pcl_write, as well as p->pcl_exec (via a pointer). That's the function pointer we'll eventually be calling.
Next, we have some code mostly focused on argument handling. We'll skip over it for now - it just translates our function prototype into terms libffi can understand.
Finally, we have another two calls to libffi:
cc = FFI_DEFAULT_ABI;
result = ffi_prep_cif(&p->cif, cc,
Py_SAFE_DOWNCAST(nargs, Py_ssize_t, int),
p->ffi_restype,
&p->atypes[0]);
if (result != FFI_OK) {
PyErr_Format(PyExc_RuntimeError,
"ffi_prep_cif failed with %d", result);
goto error;
}
result = ffi_prep_closure_loc(p->pcl_write, &p->cif, closure_fcn,
p,
p->pcl_exec);
if (result != FFI_OK) {
PyErr_Format(PyExc_RuntimeError,
"ffi_prep_closure failed with %d", result);
goto error;
}
It passes the type info from earlier into ffi_prep_cif, which writes something into p->cif.
Finally, it calls ffi_prep_closure_loc with everything it's set up so far. closure_fcn is a function defined elsewhere - it'll be important later.
So, it seems like libffi does most of the work in actually making our function pointer. Python just tells it what arguments it accepts, and libffi spits out a native function that, through magic we have yet to uncover, does the right thing.
Welp. Looks like we're going deeper.
libffi
libffi is "the portable foreign function interface library", and it's one of those C libraries that you rarely interact with directly, but somehow finds its way into every application you've ever used. (Hey, how's that going for us?)
Its main job is to smooth over the complexities of calling functions across many different CPU architectures with differing calling conventions. For example, the standard x86_64 C calling convention puts the return value of a function in the rax register - a register that ARM doesn't even have. x86_64 will typically pass the first few arguments in registers, while (32-bit) x86 usually passes everything on the stack. x86 pushes the return address to the stack, while ARM stuffs it in a "link register" instead. I'm sure more exotic architectures have even stranger quirks.
The API libffi exposes is actually pretty analogous to the CFUNCTYPE we looked at earlier - it effectively takes in a function pointer, a list of arguments, and information about the argument types and return values, and handles all the platform-specific register-wrangling from there. It's no surprise that Python delegates most of this work directly to libffi rather than trying to handle it itself.
Closure API
The part of libffi we're most interested in is its closure API - the ffi_closure_alloc and ffi_prep_closure_loc calls we saw earlier.
The documentation has one (1) single example, so let's look at that:
#include <stdio.h>
#include <ffi.h>
/* Acts like puts with the file given at time of enclosure. */
void puts_binding(ffi_cif *cif, void *ret, void* args[],
void *stream)
{
*(ffi_arg *)ret = fputs(*(char **)args[0], (FILE *)stream);
}
typedef int (*puts_t)(char *);
int main()
{
ffi_cif cif;
ffi_type *args[1];
ffi_closure *closure;
void *bound_puts;
int rc;
/* Allocate closure and bound_puts */
closure = ffi_closure_alloc(sizeof(ffi_closure), &bound_puts);
if (closure)
{
/* Initialize the argument info vectors */
args[0] = &ffi_type_pointer;
/* Initialize the cif */
if (ffi_prep_cif(&cif, FFI_DEFAULT_ABI, 1,
&ffi_type_sint, args) == FFI_OK)
{
/* Initialize the closure, setting stream to stdout */
if (ffi_prep_closure_loc(closure, &cif, puts_binding,
stdout, bound_puts) == FFI_OK)
{
rc = ((puts_t)bound_puts)("Hello World!");
/* rc now holds the result of the call to fputs */
}
}
}
/* Deallocate both closure, and bound_puts */
ffi_closure_free(closure);
return 0;
}
This looks very similar to what CPython was doing. ffi_closure_alloc allocates some space, returns a ffi_closure pointer, and also hands us a pointer to the function it made (bound_puts in this example).
Then, ffi_prep_cif sets up the "Call InterFace" (ie. cif) - here, it's hardcoded as returning an int and taking a single pointer argument.
Finally, ffi_prep_closure_loc does some magic to make-everything-work(tm), and then we can call bound_puts all we'd like!
Note the puts_binding function. This is the backing futhe fourth argument to ffi_prep_closure_loc will (somehow) be bound to our function the closure eventually calls. It receives an array of arguments, a pointer to the return value it can write to, and most importantly, user data - a single arbitrary pointer to any value we'd like. (This example calls it stream.)
This is the key to all of this: whatever value we pass as nction pointer, and will be passed to the closure callback. This is where our state lives!
Closures in CPython
Let's go back to CPython for a moment and take a look at the closure_fcn function we skipped over earlier:
static void closure_fcn(ffi_cif *cif,
void *resp,
void **args,
void *userdata)
{
PyGILState_STATE state = PyGILState_Ensure();
CThunkObject *p = (CThunkObject *)userdata;
ctypes_state *st = get_module_state_by_class(Py_TYPE(p));
_CallPythonObject(st,
resp,
p->ffi_restype,
p->setfunc,
p->callable,
p->converters,
p->flags,
args);
PyGILState_Release(state);
}
The value CPython chooses to use as its user data is... the CThunkObject itself, which contains all the information we need to call the real Python function we're wrapping, including a pointer to the Python function itself, living in managed interpreter-land.
_CallPythonObject converts the arguments back into the equivalent Python objects, but in the end, it calls PyObject_Vectorcall. This calls our Python function the way CPython would normally call it. So, we've completed the journey, hooray!
Except... we skipped over a pretty big part in the middle: we still haven't figured out what, exactly, lives at that function pointer, or how it gets its hands on the user data pointer, or how it knows what handler to call.
That's no good, is it? We're not done yet, and there's a pretty long way to go. We need to go deeper.
Closures in libffi
It's time to step out of Python-land entirely, and start writing some C.
Here's another small example of closures in libffi:
#include <stdio.h>
#include <ffi.h>
void my_closure(ffi_cif* cif, void* ret, void* args[], void *user_data) {
int* call_count = (int*)user_data;
(*call_count)++;
int arg = *((int*) args[0]);
printf("called closure with argument 0x%llx! closure called %d times.\n", arg, *call_count);
}
typedef void (*my_closure_func)(int i);
int main() {
void* code_ptr;
ffi_closure* closure = (ffi_closure*) ffi_closure_alloc(sizeof(ffi_closure), &code_ptr);
ffi_cif cif;
// take one int, return void
ffi_type* args[1] = {&ffi_type_uint32};
if (ffi_prep_cif(&cif, FFI_DEFAULT_ABI, 1, &ffi_type_void, args) != FFI_OK)
return 1;
int call_count = 0; // this will be our user data
if (ffi_prep_closure_loc(closure, &cif, my_closure, &call_count, code_ptr) != FFI_OK)
return 1;
// call it a couple times
((my_closure_func) code_ptr)(0x42424242);
((my_closure_func) code_ptr)(0xdeadbeef);
((my_closure_func) code_ptr)(0x13371337);
printf("closure was called %d times!\n", call_count);
return 0;
}
If we compile and run this:
$ gcc -lffi test.c
$ ./a.out
called closure with argument 0x42424242! closure called 1 times.
called closure with argument 0xdeadbeef! closure called 2 times.
called closure with argument 0x13371337! closure called 3 times.
closure was called 3 times!
We can, indeed, see that our function gets called as expected. We're giving it a user data pointer to a local variable in main (which will live on the stack), so there's no "cheating" going on with globals, either.
Let's look a little closer at the pointers we're working with here:
int main() {
void* code_ptr;
ffi_closure* closure = (ffi_closure*) ffi_closure_alloc(sizeof(ffi_closure), &code_ptr);
printf("ffi_closure pointer: %p\n", closure);
printf("code pointer: %p\n", code_ptr);
}
On my system, this prints the following:
ffi_closure pointer: 0x7fc0faac7010
code pointer: 0x7fc0faac7010
If I run it a few more times, I get different addresses, but they're always equal, and always end in 010. (Hey, if you scroll all the way up to the very first Python example, the first function pointer we got also ended in 010. It's almost as if this is what that uses internally.)
We'll take a look at ffi_closure_alloc in a bit, but first I want to see what actually lives at that address, and for that, we'll use one of my favorite-and-least-favorite tools, gdb!
Debugger time
gdb can be an arcane and frustrating tool to work with. I tend to use it through pwndbg, a GDB plugin that makes it... somewhat palateable to interact with.
I'm going to drop a raise(SIGINT); right at the end of main(), and then run it using GDB.
$ gdb ./a.out
GNU gdb (GDB) 14.2
[snip]
pwndbg> run
Starting program: /home/astrid/libffi/a.out
[snip]
ffi_closure pointer: 0x7ffff7fc1010
code pointer: 0x7ffff7fc1010
called closure with argument 0x42424242! closure called 1 times.
called closure with argument 0xdeadbeef! closure called 2 times.
called closure with argument 0x13371337! closure called 3 times.
closure was called 3 times!
Program received signal SIGINT, Interrupt.
[snip]
pwndbg>
I cut out a lot of the output there, since most of it is noise, but we can see that it ran our program, printed out some addresses, and then paused at our interrupt at the end (my stack trace shows it somewhere inside raise, which makes sense).
Now we can inspect the memory at our addresses:
pwndbg> x/10i 0x7ffff7fc1010
0x7ffff7fc1010: endbr64
0x7ffff7fc1014: lea r10,[rip+0xfffffffffffffff5] # 0x7ffff7fc1010
0x7ffff7fc101b: jmp QWORD PTR [rip+0x7] # 0x7ffff7fc1028
0x7ffff7fc1021: nop DWORD PTR [rax+0x0]
0x7ffff7fc1028: cmp al,0xc9
0x7ffff7fc102a: stc
0x7ffff7fc102b: idiv edi
0x7ffff7fc102d: jg 0x7ffff7fc102f
0x7ffff7fc102f: add BYTE PTR [rax-0x1f],dl
0x7ffff7fc1032: (bad)
Already, we can see some valid x86 assembly. endbr64 appears at the start of (most) functions in x86_64. The code loads its own address into register r10, and then jumps to whatever address is at 0x[...]028. Since we're trying to disassemble that address, it'll be garbage, so let's look at it directly:
pwndbg> x/a 0x7ffff7fc1028
0x7ffff7fc1028: 0x7ffff7f9c93c <ffi_closure_unix64>
So, the address it jumps to is ffi_closure_unix64, which is defined inside libffi. We'll get to this later, but let's keep looking around.
Since we have our debug symbols still intact, gdb can pretty-print structures for us. We have the address of our ffi_closure (the same one, even), so we can look inside:
pwndbg> p (ffi_closure) *0x7ffff7fc1010
$7 = {
{
tramp = "\363\017\036\372L\215\025\365\377\377\377\377%\a\000\000\000\017\037\200\000\000\000\000<\311\371\367\377\177\000",
ftramp = 0xf5158d4cfa1e0ff3
},
cif = 0x7fffffffe150,
fun = 0x555555555189 <my_closure>,
user_data = 0x7fffffffe13c
}
Alright, that's... mostly what we expected! cif is (probably, I haven't checked) the address of our ffi_cif object, fun points to our own code, and user_data points at our call_count variable.
But what's that giant byte string? tramp? It seems like that's... the machine code we just disassembled. Are they storing machine code inside our closure struct?
Looking at the struct definition of ffi_closure (with ifdefs removed) confirms:
typedef struct {
union {
char tramp[FFI_TRAMPOLINE_SIZE];
void *ftramp;
};
ffi_cif *cif;
void (*fun)(ffi_cif*,void*,void**,void*);
void *user_data;
} ffi_closure;
Hang on. Hold on.
pwndbg> vmmap
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
Start End Perm Size Offset File
0x555555554000 0x555555555000 r--p 1000 0 /home/astrid/libffi/a.out
0x555555555000 0x555555556000 r-xp 1000 1000 /home/astrid/libffi/a.out
0x555555556000 0x555555557000 r--p 1000 2000 /home/astrid/libffi/a.out
0x555555557000 0x555555558000 r--p 1000 2000 /home/astrid/libffi/a.out
0x555555558000 0x555555559000 rw-p 1000 3000 /home/astrid/libffi/a.out
0x555555559000 0x55555557a000 rw-p 21000 0 [heap]
[...snip...]
0x7ffff7f9f000 0x7ffff7fa0000 rw-p 1000 a000 /usr/lib/libffi.so.8.1.4
0x7ffff7fa0000 0x7ffff7fa2000 rw-p 2000 0 [anon_7ffff7fa0]
0x7ffff7fc1000 0x7ffff7fc2000 rwxp 1000 0 [anon_7ffff7fc1]
0x7ffff7fc2000 0x7ffff7fc6000 r--p 4000 0 [vvar]
0x7ffff7fc6000 0x7ffff7fc8000 r-xp 2000 0 [vdso]
0x7ffff7fc8000 0x7ffff7fc9000 r--p 1000 0 /usr/lib/ld-linux-x86-64.so.2
This is the virtual memory map of the process, and it shows all the regions of memory in use. Note the one containing our closure:
0x7ffff7fc1000 0x7ffff7fc2000 rwxp 1000 0 [anon_7ffff7fc1]
This page is rwx - readable, writable, and executable. It kind of has to be, if it's generating these on the fly; how else would it write the machine code there in the first place? But this is... [not great for security]*https://en.wikipedia.org/wiki/W%5EX). We'll get to this a bit later, but for now mark it down as a "big oof".
Inside libffi
ffi_closure_alloc is defined in src/closures.c. In fact, it's defined several times. By now, we're squarely in the land of #ifdefs and massively-cross-architecture C. There's a lot of noise in here I'm going to cut out, focusing only on the parts that are actively running on my own system for this example.
The main implementation, though, is this:
/* Allocate a chunk of memory with the given size. Returns a pointer
to the writable address, and sets *CODE to the executable
corresponding virtual address. */
void *
ffi_closure_alloc (size_t size, void **code)
{
void *ptr, *ftramp;
if (!code)
return NULL;
ptr = dlmalloc (size);
if (ptr)
{
msegmentptr seg = segment_holding (gm, ptr);
*code = FFI_FN (add_segment_exec_offset (ptr, seg));
if (!ffi_tramp_is_supported ())
return ptr; // we stop here on my machine :)
ftramp = ffi_tramp_alloc (0);
if (ftramp == NULL)
{
dlfree (ptr);
return NULL;
}
*code = FFI_FN (ffi_tramp_get_addr (ftramp));
((ffi_closure *) ptr)->ftramp = ftramp;
}
return ptr;
}
On my system, ffi_tramp_is_supported returns false (we'll get to what that means later), so the "second half" of this code is skipped entirely.
So, it allocates some memory with dlmalloc (which libffi ships with directly), does some pointer math, then returns that memory both as the ffi_closure*, and our code pointer. (add_segment_exec_offset seems to do nothing on my system - as far as I can tell it's mostly to support architectures with segmented memory, where you'd have to use different pointers for writing and executing).
So far, nice and simple. Just some initialization logic.
(Oh, hang on, why is the memory we get rwx, anyway? Later, later, promise!)
Seems like the real meat is in ffi_prep_closure_loc, so let's look at that. This function is architecture-specific, and we'll find our implementation of it in src/x86/ffi64.c:
ffi_status
ffi_prep_closure_loc (ffi_closure* closure,
ffi_cif* cif,
void (*fun)(ffi_cif*, void*, void**, void*),
void *user_data,
void *codeloc)
{
static const unsigned char trampoline[24] = {
/* endbr64 */
0xf3, 0x0f, 0x1e, 0xfa,
/* leaq -0xb(%rip),%r10 # 0x0 */
0x4c, 0x8d, 0x15, 0xf5, 0xff, 0xff, 0xff,
/* jmpq *0x7(%rip) # 0x18 */
0xff, 0x25, 0x07, 0x00, 0x00, 0x00,
/* nopl 0(%rax) */
0x0f, 0x1f, 0x80, 0x00, 0x00, 0x00, 0x00
};
void (*dest)(void);
char *tramp = closure->tramp;
if (cif->abi != FFI_UNIX64)
return FFI_BAD_ABI;
if (cif->flags & UNIX64_FLAG_XMM_ARGS)
dest = ffi_closure_unix64_sse;
else
dest = ffi_closure_unix64;
#if defined(FFI_EXEC_STATIC_TRAMP)
if (ffi_tramp_is_present(closure))
{
/* Initialize the static trampoline's parameters. */
if (dest == ffi_closure_unix64_sse)
dest = ffi_closure_unix64_sse_alt;
else
dest = ffi_closure_unix64_alt;
ffi_tramp_set_parms (closure->ftramp, dest, closure);
goto out;
}
#endif
/* Initialize the dynamic trampoline. */
memcpy (tramp, trampoline, sizeof(trampoline));
*(UINT64 *)(tramp + sizeof (trampoline)) = (uintptr_t)dest;
#if defined(FFI_EXEC_STATIC_TRAMP)
out:
#endif
closure->cif = cif;
closure->fun = fun;
closure->user_data = user_data;
return FFI_OK;
}
Hey, that's the assembly we saw in gdb! That's where that comes from.
We still have two different implementations living together here, one for "static trampolines" and one for "dynamic trampolines". It seems like my system uses dynamic trampolines, so we'll look at that, for now.
Cutting away the inactive code leaves... not much:
ffi_status
ffi_prep_closure_loc (ffi_closure* closure,
ffi_cif* cif,
void (*fun)(ffi_cif*, void*, void**, void*),
void *user_data,
void *codeloc)
{
static const unsigned char trampoline[24] = {
/* endbr64 */
0xf3, 0x0f, 0x1e, 0xfa,
/* leaq -0xb(%rip),%r10 # 0x0 */
0x4c, 0x8d, 0x15, 0xf5, 0xff, 0xff, 0xff,
/* jmpq *0x7(%rip) # 0x18 */
0xff, 0x25, 0x07, 0x00, 0x00, 0x00,
/* nopl 0(%rax) */
0x0f, 0x1f, 0x80, 0x00, 0x00, 0x00, 0x00
};
void (*dest)(void);
char *tramp = closure->tramp;
if (cif->abi != FFI_UNIX64)
return FFI_BAD_ABI;
if (cif->flags & UNIX64_FLAG_XMM_ARGS)
dest = ffi_closure_unix64_sse;
else
dest = ffi_closure_unix64;
/* Initialize the dynamic trampoline. */
memcpy (tramp, trampoline, sizeof(trampoline));
*(UINT64 *)(tramp + sizeof (trampoline)) = (uintptr_t)dest;
closure->cif = cif;
closure->fun = fun;
closure->user_data = user_data;
return FFI_OK;
}
This sets up the ffi_closure struct with the data we saw in the debugger. It writes the raw machine code of the trampoline to the tramp array. It also tacks a pointer to ffi_closure_unix64 (remember that from earlier?) after the machine code, right where it looks for an address to jump to.
So, the trampoline we make will end up calling ffi_closure_unix64, what does that do? We're going even further low level now, because this function is implemented directly in assembly. Our implementation is in src/x86/unix64.S:
C(ffi_closure_unix64):
L(UW8):
_CET_ENDBR
subq $ffi_closure_FS, %rsp
L(UW9):
/* cfi_adjust_cfa_offset(ffi_closure_FS) */
L(sse_entry1):
movq %rdi, ffi_closure_OFS_G+0x00(%rsp)
movq %rsi, ffi_closure_OFS_G+0x08(%rsp)
movq %rdx, ffi_closure_OFS_G+0x10(%rsp)
movq %rcx, ffi_closure_OFS_G+0x18(%rsp)
movq %r8, ffi_closure_OFS_G+0x20(%rsp)
movq %r9, ffi_closure_OFS_G+0x28(%rsp)
movq FFI_TRAMPOLINE_SIZE(%r10), %rdi /* Load cif */
movq FFI_TRAMPOLINE_SIZE+8(%r10), %rsi /* Load fun */
movq FFI_TRAMPOLINE_SIZE+16(%r10), %rdx /* Load user_data */
L(do_closure):
leaq ffi_closure_OFS_RVALUE(%rsp), %rcx /* Load rvalue */
movq %rsp, %r8 /* Load reg_args */
leaq ffi_closure_FS+8(%rsp), %r9 /* Load argp */
call PLT(C(ffi_closure_unix64_inner))
/* Deallocate stack frame early; return value is now in redzone. */
addq $ffi_closure_FS, %rsp
L(UW10):
/* cfi_adjust_cfa_offset(-ffi_closure_FS) */
/* The first byte of the return value contains the FFI_TYPE. */
cmpb $UNIX64_RET_LAST, %al
movzbl %al, %r10d
leaq L(load_table)(%rip), %r11
ja L(la)
#ifdef __CET__
/* NB: Originally, each slot is 8 byte. 4 bytes of ENDBR64 +
4 bytes NOP padding double slot size to 16 bytes. */
addl %r10d, %r10d
#endif
leaq (%r11, %r10, 8), %r10
leaq ffi_closure_RED_RVALUE(%rsp), %rsi
jmp *%r10
Since the trampoline from earlier saved its own address to r10, this function can read the ffi_closure struct, to know where to send the closure next.
Most of this work is done in the C function ffi_closure_unix64_inner.
int FFI_HIDDEN
ffi_closure_unix64_inner(ffi_cif *cif,
void (*fun)(ffi_cif*, void*, void**, void*),
void *user_data,
void *rvalue,
struct register_args *reg_args,
char *argp)
{
void **avalue;
ffi_type **arg_types;
long i, avn;
int gprcount, ssecount, ngpr, nsse;
int flags;
avn = cif->nargs;
flags = cif->flags;
avalue = alloca(avn * sizeof(void *));
gprcount = ssecount = 0;
// snip: LOTS of code for reading out the arguments from the register struct
/* Invoke the closure. */
fun (cif, rvalue, avalue, user_data);
/* Tell assembly how to perform return type promotions. */
return flags;
}
(I think it's pretty neat how it copies all the registers onto the stack in the assembly function, and then just passes rsp as the reg_args argument. There's even another entry point, ffi_closure_unix64_sse, that also copies all the xmmX registers in there, too. I just think that's cool, even if pretty standard.)
A lot of this code is dedicated to extracting the right arguments from the CPU register and stack, and stuffing it into the avalue array. I cut out most of this, since it's pretty large, but it's a fun read. (I'm also skipping over how it handles return values - there's a big jump table right after this assembly code to handle different sizes of return value, sign extension, the likes.)
Finally, it invokes the closure's callback function - the one we passed to ffi_prep_closure_loc in our own code, or in CPython, or whereever. Which means we're done, for real, maybe! We jump back out of libffi, into CPython's closure_fcn (or our own my_closure), and the call has been made!
Putting it together
So, now we can trace the entire flow of a call, from call to libffi to trampolines to callback to CPython.
In summary:
- The
CFUNCTYPEconstructor returns a class representing a function prototype - Instantiating that class with a Python function calls
_ctypes_alloc_callbackto create aCThunkObjectwith a function pointer - The thunk allocates space with
ffi_closure_alloc, which simply returns a slab ofrwxmemory ffi_prep_closure_locfills out theffi_closurestruct with a snippet of machine code and some supporting data- Now, we can call the code at our function pointer, which:
- Saves its own location to register
r10 - Jumps to
ffi_closure_unix64, using the address saved right after the trampoline code, which:- Pulls relevant data back out of the
ffi_closurestruct - Parses out the correct arguments into a flat array
- Calls back into Python's
closure_fcnwith the correct arguments, which...- Extracts a pointer to the Python function from the
CThunkObjectuser data - Converts all the arguments to their corresponding Python types
- Calls our function! :)
- Extracts a pointer to the Python function from the
- Pulls relevant data back out of the
- Saves its own location to register
What a journey.
And we only have a few elephants left in the room, too!
Why does dlmalloc return rwx pages, anyway?
(It's not supposed to do that!)
We begin at the beginning. More specifically, at #include "dlmalloc.c". Even more specifically, here:
/* Use these for mmap and munmap within dlmalloc.c. */
static void *dlmmap(void *, size_t, int, int, int, off_t);
static int dlmunmap(void *, size_t);
#define mmap dlmmap
#define munmap dlmunmap
#include "dlmalloc.c"
#undef mmap
#undef munmap
libffi doesn't compile dlmalloc.c as a source file on its own, instead, closures.c includes it directly into itself.
Before it does that, it redefines mmap and munmap, functions that typically live in libc and call directly into the kernel, to its own wrapper functions.
dlmmap's sole purpose is to get an rwx page by any means possible:
/* Map in a writable and executable chunk of memory if possible.
Failing that, fall back to dlmmap_locked. */
static void *
dlmmap (void *start, size_t length, int prot,
int flags, int fd, off_t offset)
{
void *ptr;
assert (start == NULL && length % malloc_getpagesize == 0
&& prot == (PROT_READ | PROT_WRITE)
&& flags == (MAP_PRIVATE | MAP_ANONYMOUS)
&& fd == -1 && offset == 0);
if (execfd == -1 && ffi_tramp_is_supported ())
{
ptr = mmap (start, length, prot & ~PROT_EXEC, flags, fd, offset);
return ptr;
}
/* -1 != execfd hints that we already decided to use dlmmap_locked
last time. */
if (execfd == -1 && is_mprotect_enabled ())
{
// [snipped some ifdefs, this'll fall through]
}
else if (execfd == -1 && !is_selinux_enabled ())
{
ptr = mmap (start, length, prot | PROT_EXEC, flags, fd, offset);
if (ptr != MFAIL || (errno != EPERM && errno != EACCES))
/* Cool, no need to mess with separate segments. */
return ptr;
/* If MREMAP_DUP is ever introduced and implemented, try mmap
with ((prot & ~PROT_WRITE) | PROT_EXEC) and mremap with
MREMAP_DUP and prot at this point. */
}
pthread_mutex_lock (&open_temp_exec_file_mutex);
ptr = dlmmap_locked (start, length, prot, flags, offset);
pthread_mutex_unlock (&open_temp_exec_file_mutex);
return ptr;
}
We start out simple. If we're using static trampolines (which we still aren't), it just calls mmap as usual, requesting a writable (but not executable) page.
If both PaX MPROTECT and SELinux are disabled, it'll request an RWX page by standard means, and return it if successful.
If not, it assumes it's in an environment that won't just let it get whatever it wants, and brings out the big guns.
dlmmap_locked
dlmmap_locked will, effectively, cheat:
/* Map in a chunk of memory from the temporary exec file into separate
locations in the virtual memory address space, one writable and one
executable. Returns the address of the writable portion, after
storing an offset to the corresponding executable portion at the
last word of the requested chunk. */
static void *
dlmmap_locked (void *start, size_t length, int prot, int flags, off_t offset)
{
void *ptr;
if (execfd == -1)
{
open_temp_exec_file_opts_idx = 0;
retry_open:
execfd = open_temp_exec_file ();
if (execfd == -1)
return MFAIL;
}
offset = execsize;
if (allocate_space (execfd, length))
return MFAIL;
flags &= ~(MAP_PRIVATE | MAP_ANONYMOUS);
flags |= MAP_SHARED;
ptr = mmap (NULL, length, (prot & ~PROT_WRITE) | PROT_EXEC,
flags, execfd, offset);
if (ptr == MFAIL)
{
if (!offset)
{
close (execfd);
goto retry_open;
}
if (ftruncate (execfd, offset) != 0)
{
/* Fixme : Error logs can be added here. Returning an error for
* ftruncte() will not add any advantage as it is being
* validating in the error case. */
}
return MFAIL;
}
else if (!offset
&& open_temp_exec_file_opts[open_temp_exec_file_opts_idx].repeat)
open_temp_exec_file_opts_next ();
start = mmap (start, length, prot, flags, execfd, offset);
if (start == MFAIL)
{
munmap (ptr, length);
if (ftruncate (execfd, offset) != 0)
{
/* Fixme : Error logs can be added here. Returning an error for
* ftruncte() will not add any advantage as it is being
* validating in the error case. */
}
return start;
}
mmap_exec_offset ((char *)start, length) = (char*)ptr - (char*)start;
execsize += length;
return start;
}
It'll do its best to find or create a file - any file descriptor, real or not, doesn't really matter. It'll then map that file into memory twice, once with r-x and one as rw-.
Since it's the same file backing both addresses, it can write code to the writable page, and then execute that code by jumping to the executable page. This means you technically aren't violating W^X... even though you totally are.
Well... how does it find a file? Let's check out open_temp_exec_file:
/* Instructions to look for a location to hold a temporary file that
can be mapped in for execution. */
static struct
{
int (*func)(const char *);
const char *arg;
int repeat;
} open_temp_exec_file_opts[] = {
#ifdef HAVE_MEMFD_CREATE
{ open_temp_exec_file_memfd, "libffi", 0 },
#endif
{ open_temp_exec_file_env, "LIBFFI_TMPDIR", 0 },
{ open_temp_exec_file_env, "TMPDIR", 0 },
{ open_temp_exec_file_dir, "/tmp", 0 },
{ open_temp_exec_file_dir, "/var/tmp", 0 },
{ open_temp_exec_file_dir, "/dev/shm", 0 },
{ open_temp_exec_file_env, "HOME", 0 },
#ifdef HAVE_MNTENT
{ open_temp_exec_file_mnt, "/etc/mtab", 1 },
{ open_temp_exec_file_mnt, "/proc/mounts", 1 },
#endif /* HAVE_MNTENT */
};
// [...]
int
open_temp_exec_file (void)
{
int fd;
do
{
fd = open_temp_exec_file_opts[open_temp_exec_file_opts_idx].func
(open_temp_exec_file_opts[open_temp_exec_file_opts_idx].arg);
if (!open_temp_exec_file_opts[open_temp_exec_file_opts_idx].repeat
|| fd == -1)
{
if (open_temp_exec_file_opts_next ())
break;
}
}
while (fd == -1);
return fd;
}
The function will go through several methods of getting a file, in order of priority.
The easy solution is a memfd - this has been around in the Linux kernel for a while now, and should be available on most modern systems.
Failing that, it'll try to create a file, a real file, in several directories. This can be configured with environment variables, which doesn't at all sound like a disaster waiting to happen:
/* Open a temporary file in the named directory. */
static int
open_temp_exec_file_dir (const char *dir)
{
static const char suffix[] = "/ffiXXXXXX";
int lendir, flags;
char *tempname;
#ifdef O_TMPFILE
int fd;
#endif
#ifdef O_CLOEXEC
flags = O_CLOEXEC;
#else
flags = 0;
#endif
#ifdef O_TMPFILE
fd = open (dir, flags | O_RDWR | O_EXCL | O_TMPFILE, 0700);
/* If the running system does not support the O_TMPFILE flag then retry without it. */
if (fd != -1 || (errno != EINVAL && errno != EISDIR && errno != EOPNOTSUPP)) {
return fd;
} else {
errno = 0;
}
#endif
lendir = (int) strlen (dir);
tempname = __builtin_alloca (lendir + sizeof (suffix));
if (!tempname)
return -1;
memcpy (tempname, dir, lendir);
memcpy (tempname + lendir, suffix, sizeof (suffix));
return open_temp_exec_file_name (tempname, flags);
}
At least it tries to pass the O_TMPFILE flag, which creates an "unnamed" file. However, this is not supported on all platforms or all file systems, so it'll fall back to a regular file if not.
It does attempt to clean up after itself as well:
/* Open a temporary file name, and immediately unlink it. */
static int
open_temp_exec_file_name (char *name, int flags MAYBE_UNUSED)
{
int fd;
#ifdef HAVE_MKOSTEMP
fd = mkostemp (name, flags);
#else
fd = mkstemp (name);
#endif
if (fd != -1)
unlink (name);
return fd;
}
Should none of the preset folder paths exist... say, if you were on an exotic system with a non-standard filesystem layout (...though I'm sure NixOS has /tmp, at least), it will... look through /proc/mounts for somewhere, anywhere, to create a file.
I'm honestly not sure what real-world systems would ever get this far, but they have to be out there somewhere, otherwise this code wouldn't have been written in the first place.
So... I just patched it in myself. This is mostly just out of curiosity, but if I force it to get into real files, we can actually see it in action:
$ strace ./a.out
# [...]
openat(AT_FDCWD, "/tmp", O_RDWR|O_EXCL|O_CLOEXEC) = -1 EISDIR (Is a directory)
openat(AT_FDCWD, "/tmp/ffiayUKGn", O_RDWR|O_CREAT|O_EXCL, 0600) = 3
unlink("/tmp/ffiayUKGn") = 0
write(3, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
mmap(NULL, 4096, PROT_READ|PROT_EXEC, MAP_SHARED, 3, 0) = 0x7f5b9775f000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_SHARED, 3, 0) = 0x7f5b9775e000
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x6), ...}) = 0
write(1, "ffi_closure pointer: 0x7f5b9775e"..., 36ffi_closure pointer: 0x7f5b9775e010
) = 36
write(1, "code pointer: 0x7f5b9775f010\n", 29code pointer: 0x7f5b9775f010
) = 29
We can even see that it now returns two different pointers for our ffi_closure and our code - they point to the same memory behind the scenes, but one is writable and the other is executable. This is why the entire codebase is set up to handle two different pointers there! It's neat, and cursed, but mostly neat.
If I let it get all the way to the mount scanning phase:
$ strace ./a.out
# [...]
openat(AT_FDCWD, "/etc/mtab", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0444, st_size=0, ...}) = 0
read(3, "none /mnt/wsl tmpfs rw,relatime "..., 1024) = 1024
access("/mnt/wsl", W_OK) = 0
openat(AT_FDCWD, "/mnt/wsl", O_RDWR|O_EXCL|O_CLOEXEC) = -1 EISDIR (Is a directory)
openat(AT_FDCWD, "/mnt/wsl/ffiUVJpTu", O_RDWR|O_CREAT|O_EXCL, 0600) = 4
unlink("/mnt/wsl/ffiUVJpTu") = 0
write(4, "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 4096) = 4096
mmap(NULL, 4096, PROT_READ|PROT_EXEC, MAP_SHARED, 4, 0) = 0x7f08888ec000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_SHARED, 4, 0) = 0x7f08888eb000
It'll find the first file system in my /etc/mtab. For me, that happened to be /mnt/wsl, which seems to be something WSL uses internally to sync some network configuration and not much else.
If all of this fails, then... I'm not sure what'll happen. I think it'll just fail entirely. At that point, it may be deserved.
Everything so far exists to allow libffi to write that little trampoline code snippet into memory on-the-fly. So... what if it didn't?
It's fime.
Static trampolines
I'm writing this from an Arch Linux install inside WSL, and Arch's libffi package is compiled with static trampolines disabled. It turns out Ubuntu does the same, and so does Debian.
However, static trampolines are actually on by default! There were apparently some compatibility issues with GHC that only recently seem to have resolved. Fedora enabled them last year, and NixOS did in September. I expect other distributions to start turning them back on once the downstream fixes start making their way out.
So... what are static trampolines, exactly?
Well, in the world of cybersecurity, you generally don't want to be able to write to the same memory you execute. There are many systems out there that don't allow this at all (and macOS makes you jump through countless hoops for the privilege), and there are many reasons you'd want to run "hardened" kernels with stronger restrictions. (The dynamic trampoline code has many workarounds for these hardenings and will often manage to find a way to just make it work, but bending the rules like that kind of defeats the point of them, doesn't it?)
The solution is to just... not! Instead of generating new functions at runtime, we use only ones that are baked into the library itself. That sounds simple enough in theory, but there are a lot of complexities to go along with it. We even have mmap trickery!
We saw several spots in the code earlier that branched out if static trampolines were enabled, and we mostly skipped over that portion of the code. Now's the time to give those another look.
Although static trampolines are disabled on my system, the joys of open-source means I can compile my own version of libffi with them enabled (by patching the PKGBUILD). So, let's do that, and re-run the demo from earlier to see what happens:
$ git diff
diff --git a/PKGBUILD b/PKGBUILD
index ae8c60b..288df11 100644
--- a/PKGBUILD
+++ b/PKGBUILD
@@ -22,7 +22,7 @@ build() {
local configure_options=(
# remove --disable-exec-static-tramp once ghc and gobject-introspection
# work fine with it enabled (https://github.com/libffi/libffi/pull/647)
- --disable-exec-static-tramp
+ # --disable-exec-static-tramp
--disable-multi-os-directory
--disable-static
--enable-pax_emutramp
$ makepkg -sfi --nocheck
# [...]
loading packages...
warning: libffi-3.4.6-1 is up to date -- reinstalling
warning: libffi-debug-3.4.6-1 is up to date -- reinstalling
resolving dependencies...
looking for conflicting packages...
Packages (2) libffi-3.4.6-1 libffi-debug-3.4.6-1
Total Installed Size: 0.57 MiB
Net Upgrade Size: 0.03 MiB
:: Proceed with installation? [Y/n] y
# [...]
$ ./a.out
ffi_closure pointer: 0x7fb40afd6010
code pointer: 0x7fb40afd7fc8
called closure with argument 0x42424242! closure called 1 times.
called closure with argument 0xdeadbeef! closure called 2 times.
called closure with argument 0x13371337! closure called 3 times.
closure was called 3 times!
Here, we can see that we now get totally different pointers back! Our function no longer lives inside the ffi_closure struct at all. So... where is it?
Let's return to ffi_closure_alloc for a bit:
/* Allocate a chunk of memory with the given size. Returns a pointer
to the writable address, and sets *CODE to the executable
corresponding virtual address. */
void *
ffi_closure_alloc (size_t size, void **code)
{
void *ptr, *ftramp;
if (!code)
return NULL;
ptr = dlmalloc (size);
if (ptr)
{
msegmentptr seg = segment_holding (gm, ptr);
*code = FFI_FN (add_segment_exec_offset (ptr, seg));
if (!ffi_tramp_is_supported ())
return ptr;
// [this time we get down here!]
ftramp = ffi_tramp_alloc (0);
if (ftramp == NULL)
{
dlfree (ptr);
return NULL;
}
*code = FFI_FN (ffi_tramp_get_addr (ftramp));
((ffi_closure *) ptr)->ftramp = ftramp;
}
return ptr;
}
We still dlmalloc some memory for our ffi_closure struct, but (due to the check we saw earlier), this will just be a regular rw- page, and not executable.
This means we'll have to get our code pointer some other way instead, since it can't point to non-executable memory.
We can see it calls ffi_tramp_alloc, and saves the returned pointer in the ftramp field. It then calls ffi_tramp_get_addr to turn that into a function pointer we can return as our code.
If we recall the definition of ffi_closure:
typedef struct {
union {
char tramp[FFI_TRAMPOLINE_SIZE];
void *ftramp;
};
ffi_cif *cif;
void (*fun)(ffi_cif*,void*,void**,void*);
void *user_data;
} ffi_closure;
void *ftramp is in a union next to the trampoline code array. We're using the other half of that union now, so the trampoline will be gone entirely.
Let's print the value of ftramp:
int main() {
void* code_ptr;
ffi_closure* closure = (ffi_closure*) ffi_closure_alloc(sizeof(ffi_closure), &code_ptr);
printf("ffi_closure pointer: %p\n", closure);
printf("ftramp pointer: %p\n", closure->ftramp);
printf("code pointer: %p\n", code_ptr);
// [...]
}
$ ./a.out
ffi_closure pointer: 0x7f8893a6a010
ftramp pointer: 0x55ed93461898
code pointer: 0x7f8893a6bfc8
Woah, that's an entirely different pointer, going somewhere else entirely! We'll look at the internals of ftramp in a bit.
Let's fire up gdb again to see what the memory map looks like, now:
$ gdb ./a.out
GNU gdb (GDB) 14.2
Copyright (C) 2023 Free Software Foundation, Inc.
# [...]
pwndbg> r
Starting program: /home/astrid/libffi/a.out
ffi_closure pointer: 0x7ffff7fbf010
ftramp pointer: 0x55555555a898
code pointer: 0x7ffff7fc0fc8
called closure with argument 0x42424242! closure called 1 times.
called closure with argument 0xdeadbeef! closure called 2 times.
called closure with argument 0x13371337! closure called 3 times.
closure was called 3 times!
Program received signal SIGINT, Interrupt.
# [...]
pwndbg> vmmap
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
Start End Perm Size Offset File
# [cutting out the irrelevant ones here]
0x555555559000 0x55555557a000 rw-p 21000 0 [heap]
# [...]
0x7ffff7fbf000 0x7ffff7fc0000 rw-p 1000 0 [anon_7ffff7fbf]
0x7ffff7fc0000 0x7ffff7fc1000 r-xp 1000 a000 /usr/lib/libffi.so.8.1.4
0x7ffff7fc1000 0x7ffff7fc2000 rw-p 1000 0 [anon_7ffff7fc1]
Our ftramp pointer lives on the heap, far away from the rest of our data. Our ffi_closure lives somewhere in another anonymous page, read/writable but not executable. And our code lives... in libffi.so? But it's mapped right next to the previous page? What's going on here?
Let's look at the code again:
pwndbg> x/15i 0x7ffff7fc0fc8
0x7ffff7fc0fc8: endbr64
0x7ffff7fc0fcc: sub rsp,0x10
0x7ffff7fc0fd0: mov QWORD PTR [rsp],r10
0x7ffff7fc0fd4: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1fc8
0x7ffff7fc0fdb: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0fe0: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1fd0
0x7ffff7fc0fe7: jmp r10
0x7ffff7fc0fea: nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0ff0: data16 cs nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0ffb: nop DWORD PTR [rax+rax*1+0x0]
0x7ffff7fc1000: add BYTE PTR [rax],al
0x7ffff7fc1002: add BYTE PTR [rax],al
0x7ffff7fc1004: add BYTE PTR [rax],al
0x7ffff7fc1006: add BYTE PTR [rax],al
0x7ffff7fc1008: add BYTE PTR [rax],al
We have another little bit of code. This time it seems to sit right at the end of the section.
What if we look at what's before it?
pwndbg> x/30i 0x7ffff7fc0fc8 - 0x100
0x7ffff7fc0ec8: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1eb8
0x7ffff7fc0ecf: jmp r10
0x7ffff7fc0ed2: nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0ed8: endbr64
0x7ffff7fc0edc: sub rsp,0x10
0x7ffff7fc0ee0: mov QWORD PTR [rsp],r10
0x7ffff7fc0ee4: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1ed8
0x7ffff7fc0eeb: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0ef0: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1ee0
0x7ffff7fc0ef7: jmp r10
0x7ffff7fc0efa: nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0f00: endbr64
0x7ffff7fc0f04: sub rsp,0x10
0x7ffff7fc0f08: mov QWORD PTR [rsp],r10
0x7ffff7fc0f0c: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1f00
0x7ffff7fc0f13: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0f18: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1f08
0x7ffff7fc0f1f: jmp r10
0x7ffff7fc0f22: nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0f28: endbr64
0x7ffff7fc0f2c: sub rsp,0x10
0x7ffff7fc0f30: mov QWORD PTR [rsp],r10
0x7ffff7fc0f34: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1f28
0x7ffff7fc0f3b: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0f40: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1f30
0x7ffff7fc0f47: jmp r10
0x7ffff7fc0f4a: nop WORD PTR [rax+rax*1+0x0]
0x7ffff7fc0f50: endbr64
0x7ffff7fc0f54: sub rsp,0x10
0x7ffff7fc0f58: mov QWORD PTR [rsp],r10
Huh. It's the same eight instructions over and over again. Did they just... prebuild a whole bunch of trampolines in advance? (Well, yes, but it's a bit more complicated than that.)
What happens if we try to allocate multiple closures?
#include <stdio.h>
#include <ffi.h>
int main() {
for (int i = 0; i < 10; i++) {
void* code_ptr;
ffi_closure* closure = (ffi_closure*) ffi_closure_alloc(sizeof(ffi_closure), &code_ptr);
printf("code pointer: %p\n", code_ptr);
}
}
$ ./a.out
code pointer: 0x7f69bc968fc8
code pointer: 0x7f69bc968fa0
code pointer: 0x7f69bc968f78
code pointer: 0x7f69bc968f50
code pointer: 0x7f69bc968f28
code pointer: 0x7f69bc968f00
code pointer: 0x7f69bc968ed8
code pointer: 0x7f69bc968eb0
code pointer: 0x7f69bc968e88
code pointer: 0x7f69bc968e60
Indeed, we get fc8 back again, and then it counts backwards from there.
So... will it just crash once we run out? The page is only 0x1000 bytes long. Let's try a thousand:
$ ./a.out
code pointer: 0x7f160f13ffc8
code pointer: 0x7f160f13ffa0
code pointer: 0x7f160f13ff78
# [...]
code pointer: 0x7f160f13f050
code pointer: 0x7f160f13f028
code pointer: 0x7f160f13f000
code pointer: 0x7f160f13bfc8
code pointer: 0x7f160f13bfa0
code pointer: 0x7f160f13bf78
# [...]
code pointer: 0x7f160f13b028
code pointer: 0x7f160f13b000
code pointer: 0x7f160f137fc8
code pointer: 0x7f160f137fa0
code pointer: 0x7f160f137f78
# [...]
Huh. It just keeps going, starting somewhere else once it's out. Interesting.
Fun wih memory maps
Okay, enough playing around, back to the code. Time to figure out what it's allocating, and where.
We know that when we allocate a closure using static trampolines, it also calls ffi_tramp_alloc to fill out the ftramp pointer. Let's see what that does:
/*
* Allocate a trampoline and return its opaque address.
*/
void *
ffi_tramp_alloc (int flags)
{
struct tramp *tramp;
ffi_tramp_lock();
if (!ffi_tramp_init () || flags != 0)
{
ffi_tramp_unlock();
return NULL;
}
if (!tramp_table_alloc ())
{
ffi_tramp_unlock();
return NULL;
}
tramp = tramp_globals.free_tables->free;
tramp_del (tramp);
ffi_tramp_unlock();
return tramp;
}
A lot of this code is linked-list-wrangling and locking, and I'll skip over most of the boring parts. There's most of a memory allocator in here (separate from the all of a memory allocator that lives in dlmalloc.c).
In short: what we were looking at earlier was a trampoline table. tramp_table_alloc ensures there's one available (and makes a new one if it's all used), and tramp_globals.free_tables->free gets you the last available trampoline off that table. (This is also why we were counting "backwards" earlier - you get the last one first.)
We'll learn more about what's inside a trampoline table later, but before we can worry about that, we need to look at the setup. A lot of that lives in ffi_tramp_init:
/*
* Initialize the static trampoline feature.
*/
static int
ffi_tramp_init (void)
{
long page_size;
if (tramp_globals.status == TRAMP_GLOBALS_PASSED)
return 1;
if (tramp_globals.status == TRAMP_GLOBALS_FAILED)
return 0;
if (ffi_tramp_arch == NULL)
{
tramp_globals.status = TRAMP_GLOBALS_FAILED;
return 0;
}
tramp_globals.free_tables = NULL;
tramp_globals.nfree_tables = 0;
/*
* Get trampoline code table information from the architecture.
*/
tramp_globals.text = ffi_tramp_arch (&tramp_globals.size,
&tramp_globals.map_size);
tramp_globals.ntramp = tramp_globals.map_size / tramp_globals.size;
page_size = sysconf (_SC_PAGESIZE);
if (page_size >= 0 && (size_t)page_size > tramp_globals.map_size)
return 0;
if (ffi_tramp_init_os ())
{
tramp_globals.status = TRAMP_GLOBALS_PASSED;
return 1;
}
tramp_globals.status = TRAMP_GLOBALS_FAILED;
return 0;
}
This looks promising. Some more memory management, but then we see this bit:
tramp_globals.text = ffi_tramp_arch (&tramp_globals.size,
&tramp_globals.map_size);
tramp_globals.ntramp = tramp_globals.map_size / tramp_globals.size;
ffi_tramp_arch is another platform-specific function. Ours is defined in src/x86/ffi64.c again, right at the bottom:
#if defined(FFI_EXEC_STATIC_TRAMP)
void *
ffi_tramp_arch (size_t *tramp_size, size_t *map_size)
{
extern void *trampoline_code_table;
*map_size = UNIX64_TRAMP_MAP_SIZE;
*tramp_size = UNIX64_TRAMP_SIZE;
return &trampoline_code_table;
}
#endif
"Code table" would indeed be a good word to describe what we saw earlier. We have some constants - UNIX64_TRAMP_SIZE is 40 (for us), and UNIX64_TRAMP_MAP_SIZE is 1 << 12, or 4K. That matches up with our earlier observations, too!
We'll find our assembly in trampoline_code_table, which lives in src/x86/unix64.S. I'm going to strip away some ifdefs again (we're ENDBR_PRESENT and !__ILP32__):
#define X86_DATA_OFFSET 4077
#define X86_CODE_OFFSET 4073
.align UNIX64_TRAMP_MAP_SIZE
.globl trampoline_code_table
FFI_HIDDEN(C(trampoline_code_table))
C(trampoline_code_table):
.rept UNIX64_TRAMP_MAP_SIZE / UNIX64_TRAMP_SIZE
_CET_ENDBR
subq $16, %rsp /* Make space on the stack */
movq %r10, (%rsp) /* Save %r10 on stack */
movq X86_DATA_OFFSET(%rip), %r10 /* Copy data into %r10 */
movq %r10, 8(%rsp) /* Save data on stack */
movq X86_CODE_OFFSET(%rip), %r10 /* Copy code into %r10 */
jmp *%r10 /* Jump to code */
.align 8
.endr
ENDF(C(trampoline_code_table))
.align UNIX64_TRAMP_MAP_SIZE
This is exactly the code we saw in the disassembly, just a little harder to read.
The .rept UNIX64_TRAMP_MAP_SIZE / UNIX64_TRAMP_SIZE directive instructs the assembler to repeat this snippet over and over again to fill the whole page. Which, again, is what we saw! Things are starting to add up again.
The assembly itself reads some data at a specific offset relative to itself - 4073 and 4077 bytes, respectively. If we return to our gdb disassembly, we'll see that it's been helpful enough to resolve these offsets for us:
0x7ffff7fc0fc8: endbr64
0x7ffff7fc0fcc: sub rsp,0x10
0x7ffff7fc0fd0: mov QWORD PTR [rsp],r10
0x7ffff7fc0fd4: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1fc8
0x7ffff7fc0fdb: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0fe0: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1fd0
0x7ffff7fc0fe7: jmp r10
Looking back at our memory map, now:
0x7ffff7fc0000 0x7ffff7fc1000 r-xp 1000 a000 /usr/lib/libffi.so.8.1.4
0x7ffff7fc1000 0x7ffff7fc2000 rw-p 1000 0 [anon_7ffff7fc1]
We can see that these point into the page directly after our code.
Alright, later is now: is this what a trampoline table is? We can see all of this get constructed in tramp_table_map:
static int
tramp_table_map (struct tramp_table *table)
{
char *addr;
/*
* Create an anonymous mapping twice the map size. The top half will be used
* for the code table. The bottom half will be used for the parameter table.
*/
addr = mmap (NULL, tramp_globals.map_size * 2, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED)
return 0;
/*
* Replace the top half of the anonymous mapping with the code table mapping.
*/
table->code_table = mmap (addr, tramp_globals.map_size, PROT_READ | PROT_EXEC,
MAP_PRIVATE | MAP_FIXED, tramp_globals.fd, tramp_globals.offset);
if (table->code_table == MAP_FAILED)
{
(void) munmap (addr, tramp_globals.map_size * 2);
return 0;
}
table->parm_table = table->code_table + tramp_globals.map_size;
return 1;
}
We allocate a slab of memory and split it into two - one half becomes the code_table, and the other the parm_table. These are the two halves of our trampoline table! The big chunk of trampoline code lives in code_table, and they read from the parm_table (parameter table) just below it.
I believe we are overdue a diagram, so here it is:
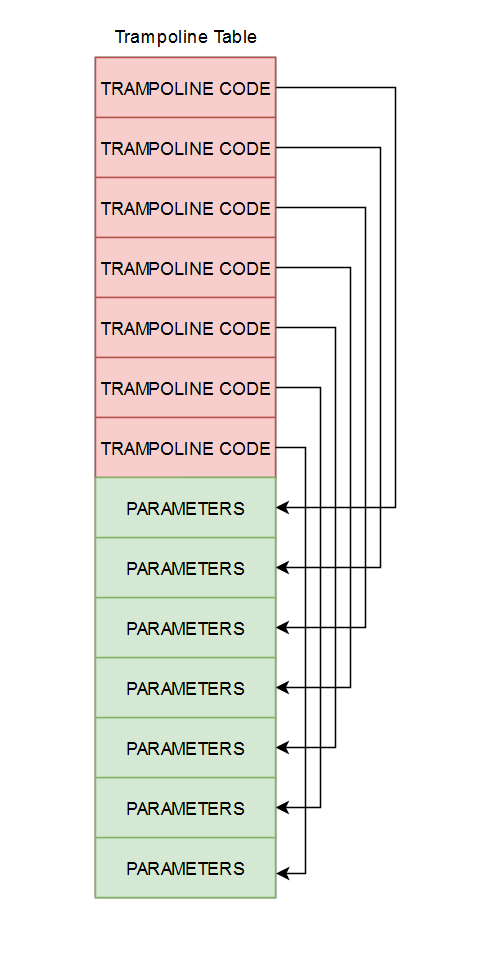
Since the trampoline uses rip-relative indexing (ie. relative to itself), it'll always find its corresponding parameters chunk in the region below.
But... how, exactly are we getting the trampoline code into the table? It's by definition not writable (that's the point of static trampolines), so we can't copy the code in there. Instead, it maps from a file.
So, where do tramp_globals.fd and tramp_globals.offset come from? We skipped over a part of the initialization earlier - the call to ffi_tramp_init_os - so let's get to that now:
static int
ffi_tramp_init_os (void)
{
if (ffi_tramp_get_libffi ())
return 1;
return ffi_tramp_get_temp_file ();
}
static int
ffi_tramp_get_libffi (void)
{
FILE *fp;
char file[PATH_MAX], line[PATH_MAX+100], perm[10], dev[10];
unsigned long start, end, offset, inode;
uintptr_t addr = (uintptr_t) tramp_globals.text;
int nfields, found;
snprintf (file, PATH_MAX, "/proc/%d/maps", getpid());
fp = fopen (file, "r");
if (fp == NULL)
return 0;
found = 0;
while (feof (fp) == 0) {
if (fgets (line, sizeof (line), fp) == 0)
break;
nfields = sscanf (line, "%lx-%lx %9s %lx %9s %ld %s",
&start, &end, perm, &offset, dev, &inode, file);
if (nfields != 7)
continue;
if (addr >= start && addr < end) {
tramp_globals.offset = offset + (addr - start);
found = 1;
break;
}
}
fclose (fp);
if (!found)
return 0;
tramp_globals.fd = open (file, O_RDONLY);
if (tramp_globals.fd == -1)
return 0;
/*
* Allocate a trampoline table just to make sure that the trampoline code
* table can be mapped.
*/
if (!tramp_table_alloc ())
{
close (tramp_globals.fd);
tramp_globals.fd = -1;
return 0;
}
return 1;
}
Let's go through this bit by bit:
uintptr_t addr = (uintptr_t) tramp_globals.text;
First, it reads tramp_globals.text. This value came from ffi_tramp_arch, and on x86_64, will point to the trampoline table from the assembly file. (Code is text. Make it make sense.)
It's worth noting that this is the "regular" copy of libffi.so loaded into memory, so it'll be surrounded by all sorts of other code. We can't use this directly, since there won't be a writable parameter table below it.
snprintf (file, PATH_MAX, "/proc/%d/maps", getpid());
fp = fopen (file, "r");
if (fp == NULL)
return 0;
found = 0;
while (feof (fp) == 0) {
if (fgets (line, sizeof (line), fp) == 0)
break;
nfields = sscanf (line, "%lx-%lx %9s %lx %9s %ld %s",
&start, &end, perm, &offset, dev, &inode, file);
if (nfields != 7)
continue;
if (addr >= start && addr < end) {
tramp_globals.offset = offset + (addr - start);
found = 1;
break;
}
}
fclose (fp);
if (!found)
return 0;
Next, it opens /proc/[pid]/maps (where [pid] is its own process ID), and reads from this file. This is a special file provided by the kernel that'll spit out a memory map of a process, just like the one gdb gave us (but less colorful):
$ cat /proc/255736/maps
555555554000-555555555000 r--p 00000000 08:20 600360 /home/astrid/libffi/a.out
555555555000-555555556000 r-xp 00001000 08:20 600360 /home/astrid/libffi/a.out
555555556000-555555557000 r--p 00002000 08:20 600360 /home/astrid/libffi/a.out
# [...] it's this again you know it
It then scans through this file, line by line, looking for the region that contains our trampoline code table from earlier. It'll note down its offset relative to the start of the region, as well.
tramp_globals.fd = open (file, O_RDONLY);
if (tramp_globals.fd == -1)
return 0;
Then, libffi will open itself with the filename it found in the memory map. It leaves the file descriptor in tramp_globals.fd... which is what we map into the trampoline tables!
Since it knows how far into the file the trampoline code lives (and on Linux, the ELF binary is loaded directly into memory, so these will match up), it can then map just that code into memory by the offset parameter.
There's nothing stopping it from mapping this code into memory multiple times, in multiple places. Problem solved!
(This is indeed how we were able to keep allocating more and more closures earlier. Whenever it ran out of space in one table, it just mapped in a new pair of code/data pages and kept going.)
Here's another diagram for your troubles:
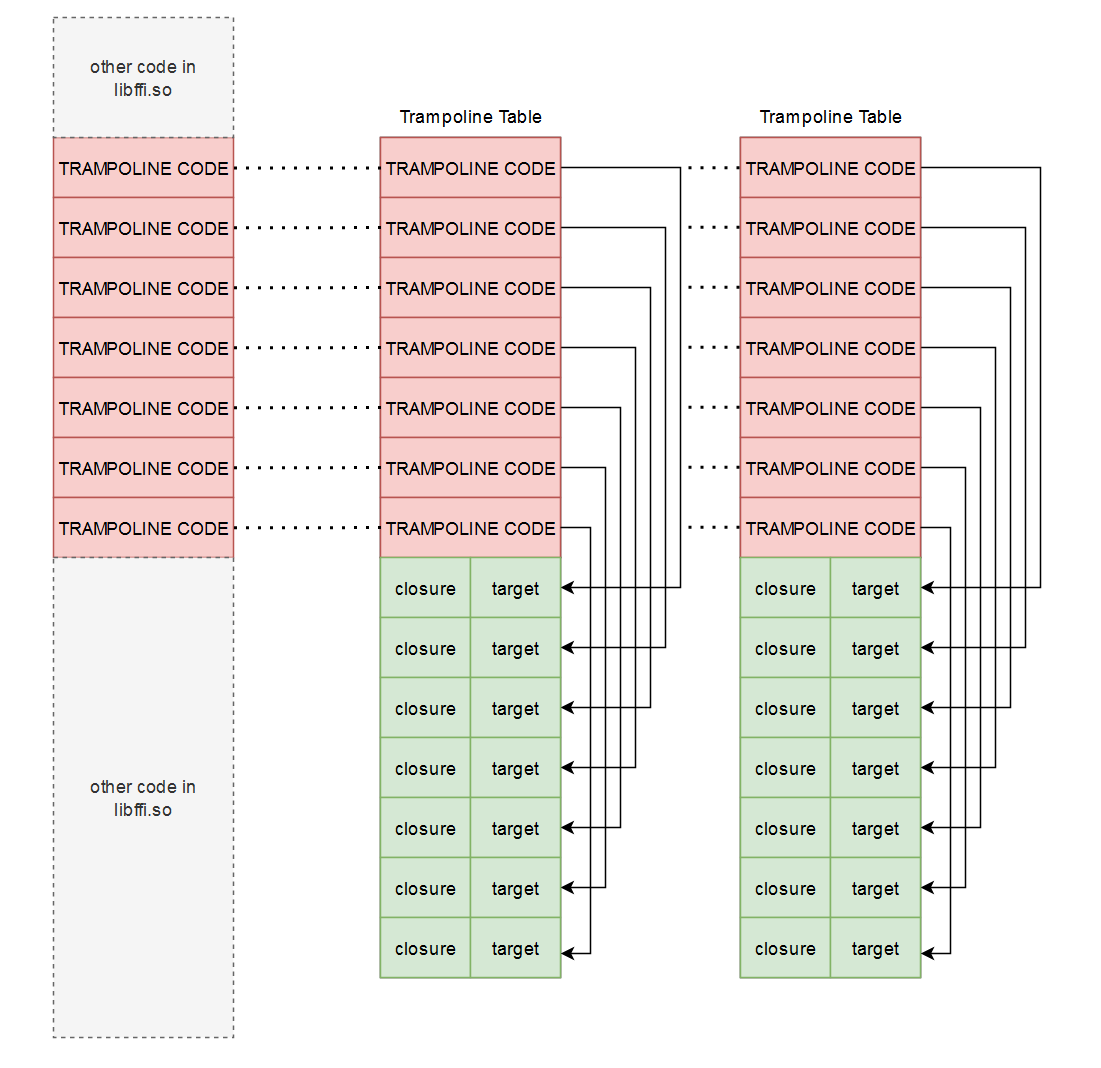
Trampoline parameters
The trampoline structs get set up back in tramp_table_alloc. It's mostly table-management, but there's a little bit that assigns each trampoline its code and parameter pointers from the tables:
/*
* Populate the trampoline table free list. This will also add the trampoline
* table to the global list of trampoline tables.
*/
size = tramp_globals.size;
code = table->code_table;
parm = table->parm_table;
for (i = 0; i < tramp_globals.ntramp; i++)
{
tramp = &tramp_array[i];
tramp->table = table;
tramp->code = code;
tramp->parm = (struct tramp_parm *) parm;
tramp_add (tramp);
code += size;
parm += size;
}
The trampoline struct is defined in tramp.c itself and is not part of the public API - until now, we've only really seen it being used through an opaque pointer (eg. ffi_tramp_get_addr).
The struct looks like this:
struct tramp
{
struct tramp *prev;
struct tramp *next;
struct tramp_table *table;
void *code;
struct tramp_parm *parm;
};
We have your usual linked list prev/next pointers, a pointer back to the root table, and our pointers into each half of the our memory-mapped slabs from earlier.
The code pointer points to one of the many duplicate trampoline functions we mapped into memory earlier, and parm points to the memory we mapped just below each code table, the one the trampoline reads "forwards" into.
These parameters get initialized in ffi_prep_closure_loc, the function that would've written the dynamic trampoline into memory:
ffi_status
ffi_prep_closure_loc (ffi_closure* closure,
ffi_cif* cif,
void (*fun)(ffi_cif*, void*, void**, void*),
void *user_data,
void *codeloc)
{
static const unsigned char trampoline[24] = {
/* endbr64 */
0xf3, 0x0f, 0x1e, 0xfa,
/* leaq -0xb(%rip),%r10 # 0x0 */
0x4c, 0x8d, 0x15, 0xf5, 0xff, 0xff, 0xff,
/* jmpq *0x7(%rip) # 0x18 */
0xff, 0x25, 0x07, 0x00, 0x00, 0x00,
/* nopl 0(%rax) */
0x0f, 0x1f, 0x80, 0x00, 0x00, 0x00, 0x00
};
void (*dest)(void);
char *tramp = closure->tramp;
if (cif->abi != FFI_UNIX64)
return FFI_BAD_ABI;
if (cif->flags & UNIX64_FLAG_XMM_ARGS)
dest = ffi_closure_unix64_sse;
else
dest = ffi_closure_unix64;
#if defined(FFI_EXEC_STATIC_TRAMP)
if (ffi_tramp_is_present(closure))
{
/* Initialize the static trampoline's parameters. */
if (dest == ffi_closure_unix64_sse)
dest = ffi_closure_unix64_sse_alt;
else
dest = ffi_closure_unix64_alt;
ffi_tramp_set_parms (closure->ftramp, dest, closure);
goto out;
}
#endif
/* Initialize the dynamic trampoline. */
memcpy (tramp, trampoline, sizeof(trampoline));
*(UINT64 *)(tramp + sizeof (trampoline)) = (uintptr_t)dest;
#if defined(FFI_EXEC_STATIC_TRAMP)
out:
#endif
closure->cif = cif;
closure->fun = fun;
closure->user_data = user_data;
return FFI_OK;
}
We can ignore the byte array entirely - we're not using it. Let's strip away the other half, leaving the parts relevant for static trampolines (and simplify the control flow a little):
ffi_status
ffi_prep_closure_loc (ffi_closure* closure,
ffi_cif* cif,
void (*fun)(ffi_cif*, void*, void**, void*),
void *user_data,
void *codeloc)
{
void (*dest)(void);
if (cif->abi != FFI_UNIX64)
return FFI_BAD_ABI;
/* Initialize the static trampoline's parameters. */
if (cif->flags & UNIX64_FLAG_XMM_ARGS)
dest = ffi_closure_unix64_sse_alt;
else
dest = ffi_closure_unix64_alt;
ffi_tramp_set_parms (closure->ftramp, dest, closure);
closure->cif = cif;
closure->fun = fun;
closure->user_data = user_data;
return FFI_OK;
}
We still initialize the ffi_closure struct like before, but instead of writing any machine code, we call another function, ffi_tramp_set_parms, to initialize the trampoline:
/*
* Set the parameters for a trampoline.
*/
void
ffi_tramp_set_parms (void *arg, void *target, void *data)
{
struct tramp *tramp = arg;
ffi_tramp_lock();
tramp->parm->target = target;
tramp->parm->data = data;
ffi_tramp_unlock();
}
Here it is! The tramp_parm struct (what a beautiful name) looks like this:
struct tramp_parm
{
void *data;
void *target;
};
We can extend our diagram with this information:
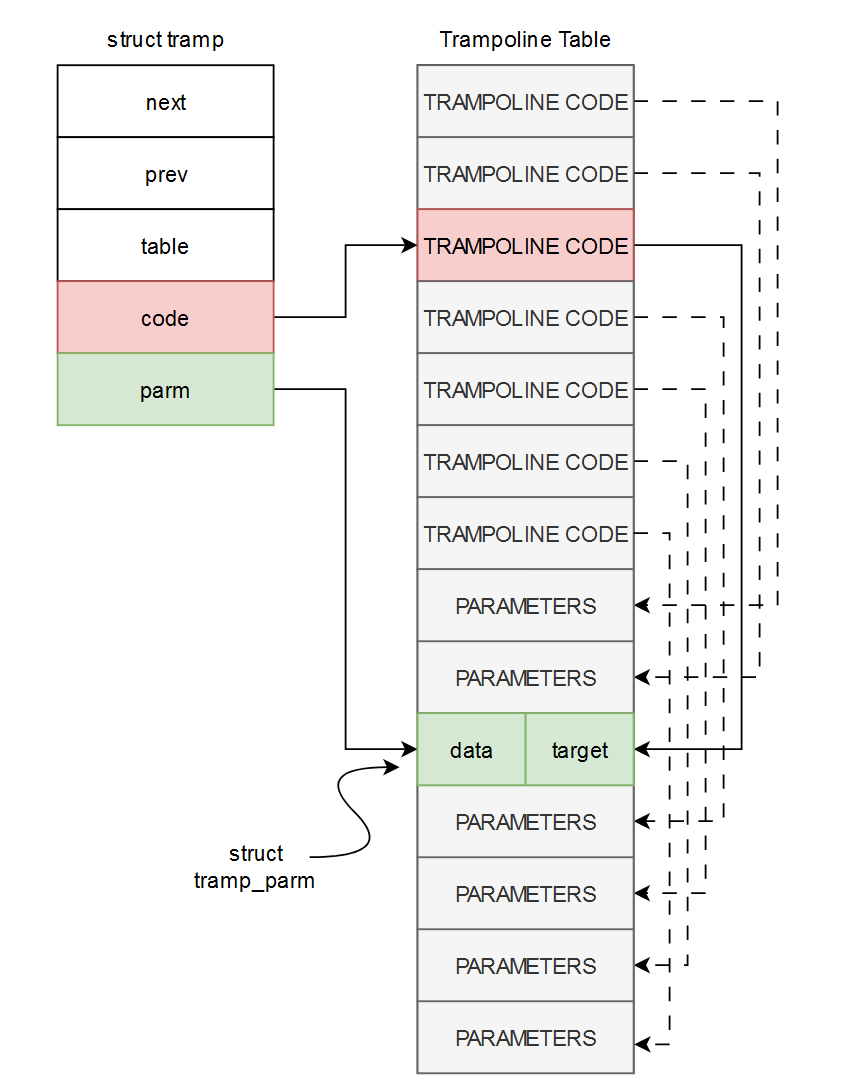
If we recall what the trampoline code looks like:
0x7ffff7fc0fc8: endbr64
0x7ffff7fc0fcc: sub rsp,0x10
0x7ffff7fc0fd0: mov QWORD PTR [rsp],r10
0x7ffff7fc0fd4: mov r10,QWORD PTR [rip+0xfed] # 0x7ffff7fc1fc8
0x7ffff7fc0fdb: mov QWORD PTR [rsp+0x8],r10
0x7ffff7fc0fe0: mov r10,QWORD PTR [rip+0xfe9] # 0x7ffff7fc1fd0
0x7ffff7fc0fe7: jmp r10
It saves both the data and the target to the stack, and then jumps to the target.
In this case, the data will be our ffi_closure pointer (which contains the user data and such), and the target will be ffi_closure_unix64_alt. This is another bit of raw assembly:
C(ffi_closure_unix64_alt):
_CET_ENDBR
movq 8(%rsp), %r10 /* Load closure in r10 */
addq $16, %rsp /* Restore the stack */
jmp C(ffi_closure_unix64)
ENDF(C(ffi_closure_unix64_alt))
There are a few reasons we need this extra indirection. Since we could map the trampoline anywhere in memory, we can't use relative jumps back into libffi functions, and we won't have absolute pointers until at runtime, when the libraries are loaded and functions resolved. ffi_closure_unix64 expects a pointer to our ffi_closure in the r10 register, which was easy for dynamic trampolines when the machine code lived in the same struct.
This is why the trampoline saves the data pointer to the stack. It needs r10 for itself in order to resolve the jump target (because of x86, and the way it is), but once it jumps, it's lost track of "where it was", and where to find the data pointer. Hence, we tuck the data pointer away on the stack, temporarily. There are probably tons of other ways around this issue (like just using multiple registers), but I figure this is either the smallest, fastest, or simplest, or all of the above.
Once we jump to ffi_closure_unix64, the rest of the call proceeds just like it did with dynamic trampolines - unpacks the arguments, calls the closure callback, and we land back in CPython or whereever.
But, this way, we do it without any rwx pages at all!
Conclusion
I wrote this post in about 12 consecutive hours, because I had a question and I couldn't let it go until I had an answer. Now I feel like I understand libffi more than I probably should, which I'm sure is only a good thing.
I'm not good at conclusions. Maybe one day soon I'll figure out how emutramp works and go down another rabbit hole. I think it's where the kernel recognizes the trampoline patterns and lets you jump to them anyway even if they're not mapped as executable at all. I'm sure that can't possibly go wrong.